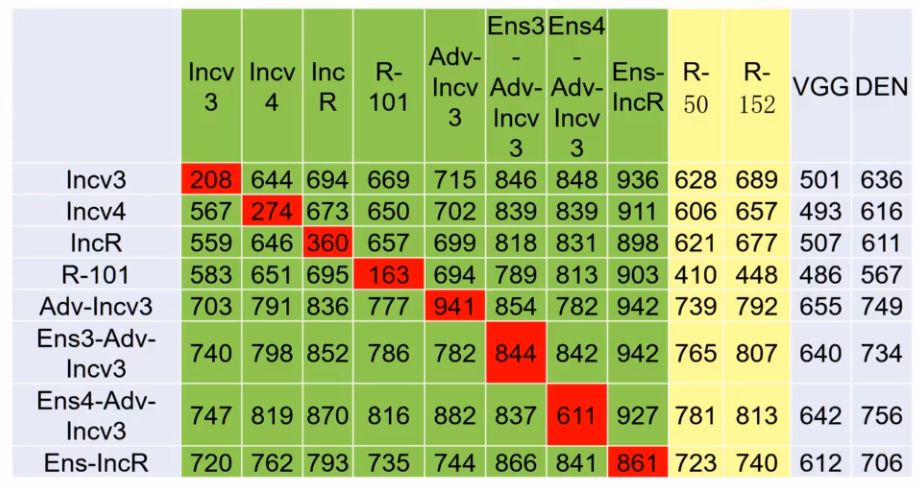
This article is contributed by Zhang Zihao, a graduate student of Tongji University, and introduces the frontier research field of artificial intelligence and information security: deep learning offensive and defensive confrontation. This article introduces how to use adversarial samples to modify pictures and mislead the neural network into referring to a deer as a horse; it also interprets the algorithm model of the Tsinghua team, the three champions of the NIPS 2017 neural network confrontation attack and defense competition. Part of the content of the article comes from the report of the 2018 CNCC China Computer Conference - Artificial Intelligence and Information Security. GAN is not a stick at all, so don't be too deceived: Panda becomes a monkey, and Shan mistakenly thinks of a dog Adversarial examples are not misleading only in the final prediction stage, but are misleading from the beginning of the feature extraction process In the NIPS 2017 Neural Network Attack and Defense Competition, scholars from Tsinghua University adopted a variety of deep learning model ensemble attack schemes, and the trained attack samples have good universality and transferability. The full text is about 3500 words. It may take several times to read the following song Fat Tiger and Wu Yifan, the border is so blurry Wang Leehom and Jacky Cheung look so similar Face recognition, autonomous driving, face payment, catching fugitives, beauty live broadcasts... The deep integration of artificial intelligence and the real economy has completely changed our lives. Neural networks and deep learning seem to be incredibly powerful and trustworthy. But artificial intelligence is the smartest, but also the dumbest. In fact, only a small amount of money can mislead the most advanced deep learning models into falsehoods. Giant panda = Gibbon As early as 2015, Ian Goodfellow, the "father of generative adversarial neural network GAN", demonstrated a successful case of attacking neural network deception at the ICLR conference. Add interference that is hard to see with the naked eye to the original giant panda image to generate adversarial samples. That would trick a Google-trained neural network into thinking it was 99.3% a gibbon. alps = dog 2017 NIPS Adversarial Sample Offense and Defense Competition Case: Alps pictures were tampered with by neural networks and misjudged as dogs, and puffer fish were misjudged as crabs. Adversarial examples are not only applicable to images and neural networks, but also to algorithms such as support vector machines and decision trees. So, what are the specific ways to turn artificial intelligence into artificial mental retardation? Artificial Intelligence: Escape Attack, White Box/Black Box, Adversarial Examples Escape attacks can be divided into white box attacks and black box attacks. The white-box attack is to attack on all the information and parameters inside the machine learning model that has been obtained, maximize the loss function, and directly calculate the adversarial samples. The black-box attack is to generate adversarial samples inversely only through the input and output of the model when the neural network structure is a black box. The left picture below is a white box attack (self-attack and self-inflicted), and the right picture is a black box attack (use the stone of another mountain to attack the jade of this mountain). An escape attack on a machine learning model, bypassing the discrimination of deep learning and generating deceptive results, the modification constructed by the attacker on the original image is called an adversarial sample. Neural network adversarial sample generation and attack and defense is a very interesting and promising research direction. In 2018, Ian Goodfellow made another big move, not only deceiving the neural network, but also deceiving the human eye. We propose the first adversarial example that can fool humans. The left picture below is the original picture of the cat. The right picture is generated after the interference of the confrontation sample. For the right picture, both the neural network and the human eye think it is a dog. In the image below, the green box is the original image of the cat. The upper left shows that the higher the number of target depth models attacked, the more dog-like the resulting image looks to humans. The bottom left shows the adversarial examples generated against 10 models attacked, when eps = 8, the human subjects have recognized it as a dog. In addition, artificial intelligence also faces various information security challenges such as model inference attacks, denial of service attacks, and sensor attacks. How tricky are human adversarial samples? The adversarial sample will add interference that is difficult to detect with the naked eye on the original image, but the difference from the original image can still be seen. The left image below is the adversarial sample, and the right image is the original panda image. The adversarial examples are not misleading only at the final prediction stage, but are misleading from the beginning of the feature extraction process. The following figure shows the attention region of neuron 147 in the normal deep learning model and the adversarial example, respectively. In the normal model, neuron 147 focuses on information about the bird's head. In the adversarial example, neuron 147 is completely misguided, and the region of interest is disorganized. It also shows that adversarial examples are not generated according to semantics, and they are not intelligent. Moreover, as described next, adversarial samples are very sensitive to the image preprocessing process, and any area screenshots, zooming in and out, and changing models can easily invalidate the adversarial samples. In fact, if you slightly zoom in or zoom out the giant panda image that has been attacked and tampered with, or directly take a part of the image and run it on other public image recognition models (such as Baidu Image Recognition), the recognition result is still a giant panda . This means that adversarial samples are only valid for the specified images and attack models, and are very sensitive to preprocessing processes such as region screenshots, zoom-in and zoom-out. That is, if you want to fool more other deep learning models, you need to include as many known deep learning models as possible when training generated adversarial examples. How NIPS Champions Do It In 2017, Ian Goodfellow, the father of Generative Adversarial Neural Networks (GAN), took the lead in organizing NIPS' Adversarial Attacks and Defences (Neural Network Against Attack and Defense Competition). Tsinghua University doctoral students Dong Yinpeng, Liao Fangzhou, Pang Tianyu and their advisors Zhu Jun, Hu Xiaolin, Li Jianmin, and Su Hang won the championship in all three projects in the competition. The Tsinghua University team adopted the attack scheme of a variety of deep learning models, and proposed seven attack models by training 30,000 images on the Image.Net website. The ensemble attack considers three known deep learning models, Inception V3, ResNet, and Inception ResNet V2, and the trained attack samples have good universality and transferability. The image below shows their test of the attack using the FGSM model: The horizontal line is the name of the attack model, and the vertical column is the name of the defense model. The numbers in the table represent the number of pictures successfully defended by the defense model for every 1000 attack pictures. The more effective the rampant model attack. Red means attack and defense with the same model (white box attack). It can be seen that the following is an ordered sequence The success rate of white-box attacks is much greater than that of black-box attacks. How to improve the transferability of black-box attacks and realize cross-model black-box attacks is an important issue. It can be seen from the vertical column of Adv-Incv3 that the defensive model after confrontation training is very powerful. It can even achieve a defensive success rate of 94.1%. Therefore, introducing adversarial samples into the training data set for adversarial training is an effective defensive strategy, which is equivalent to the fact that soldiers use real battlefield conditions when they usually train, and they will naturally not hesitate to go to the battlefield. It can be seen from the vertical column of Ens4-Adv-Incv3 that the defensive model after training with multiple model sets is very powerful. As the so-called "use the stones of the five mountains and other mountains to attack the jade of this mountain" and "the sea has been difficult for water", the defense model trained by using multiple depth models must be the best of all. Defense Group: Image Noise Reduction Strategies Adversarial training (using the real battlefield as a training ground): Add adversarial samples (adversarial training) when training the model. Adversarial examples are generated online along with the model training process. Although time-consuming, the trained model is robust Improved HGD noise reduction algorithm: Denoising at the pixel level does not really remove noise, and traditional pixel denoising methods are all ineffective. Using the improved HGD noise reduction algorithm based on CNN, only 750 training images are used, which greatly saves training time, and the model has good transferability. How NIPS Champions Do It Voice commands that mislead the car This method has been realized by Chen Kai, a professor at the University of Chinese Academy of Sciences. By interfering with the encoding of the song played by the car stereo, although the human ear still sounds the original song, in fact, the "Open the door" command was sent secretly through the voice of WeChat. The author of this article, Zhang Zihao, proposed another idea, using the Raspberry Pi microcomputer to transmit FM radio to play the songs after the interference, and directly interfere with the car radio. Chen Kai said that he has tried this method, and the key to determining the success rate of interference is to filter external noise interference. Hack the local AI model directly Li Kang, head of the 360 ​​Intelligent Security Research Institute, believes that the next hot spot in artificial intelligence and information security: the risk of deep learning model parameters being stolen and data security. With the advent of the era of edge computing and intelligent mobile terminals, the deployment of local AI applications on mobile terminals is becoming more and more extensive. From the face-to-face unlocking of the iPhone X, to the deployment of AI chips on mobile phones by Huawei and Qualcomm. Running AI applications locally on mobile terminals can effectively solve problems such as delay, transmission bandwidth, and leakage of user privacy, but it also brings data security issues of local deep learning models. After a simple inversion, many local AI applications can be cracked, and the basic parameters of the Caffe model can even be known. Some developers will use AES encryption to encapsulate the model, but everyone knows that the AES key must also be stored in a local file. Sometimes the neural network structure of this model can be judged by tracking the memory access of AI applications. Therefore, when AI developers deploy AI applications to mobile terminals and embedded devices, they must consult the security team in advance to ensure the security of model data. Further reading Introduction of NIPS 2017 Neural Network Against Offensive and Defense Competition: Competition grouping rules The game is for three groups of players to attack and defend each other Targed Attack group: The organizing committee gave 5,000 original images and the target misleading result dataset corresponding to each image, and formulated a requirement to refer to a deer as a horse Non-ratgeted Attack group: as long as you don't recognize a deer Defense group: correctly identify images that have been attacked by adversarial samples from other participating groups Attack group: Adversarial sample generation strategy Aggregate attack (stones from other mountains can attack jade): Attack a ensemble of multiple known deep learning models instead of breaking them one by one. For example, if the three models of ResNet, VGG, and Inception are attacked together as a unified large model, and then the trained model is used to attack AlexNet, the success rate will be greatly improved. The ensemble attack of multiple models can be carried out at the bottom layer of the model, the predicted value, and the loss function. Using this method can greatly improve the universality and transferability of adversarial sample attacks. Improved FGSM model: multi-step iteration, with target, and momentum is introduced, which greatly improves the transferability of adversarial examples. Air Circulation Fryer,Electric Oil Less Fryer,Large Capacity Air Fryer,Multi Function Air Fryer Oven Ningbo ATAP Electric Appliance Co.,Ltd , https://www.atap-airfryer.com