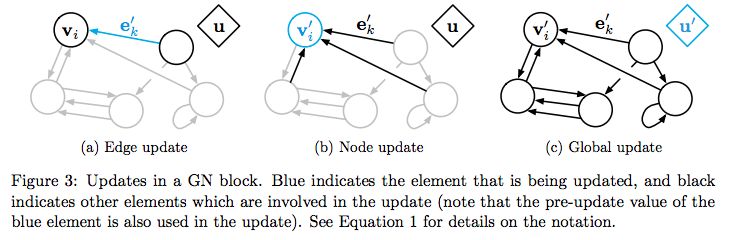
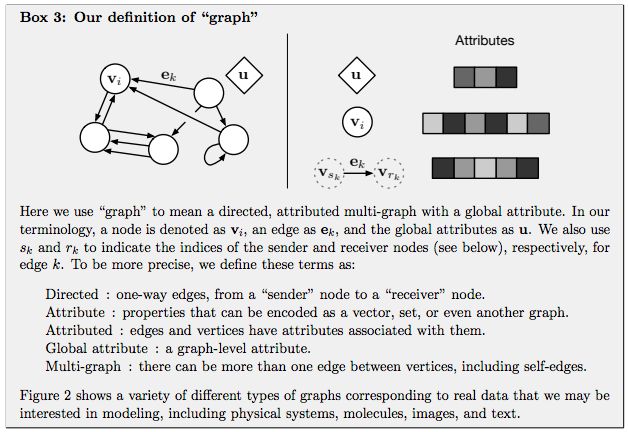
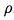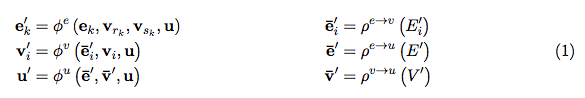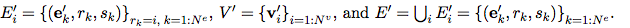DeepMind, together with 27 authors from Google Brain, MIT and other institutions, published a heavy paper and proposed a "Graph network", which combines end-to-end learning with inductive reasoning, and is expected to solve the problem that deep learning cannot perform relational reasoning. As a benchmark in the industry, the trend of DeepMind has always been the focus of attention in the AI ​​industry. Recently, this world's top AI laboratory seems to have focused on exploring "relationships". Since June, several papers on "relationships" have been published, such as: Relational inductive bias for physical construction in humans and machines Relational Deep Reinforcement Learning Relational RNN (Relational Recurrent Neural Networks) There are many papers, but if any paper is most worthy of reading, then this one must be selected-"Relationship Induction Bias, Deep Learning and Graph Network". This article combines 27 authors of DeepMind, Google Brain, MIT, and the University of Edinburgh (22 of which are from DeepMind), using 37 pages to fully describe the relationship induction bias and the graph network (Graph network). DeepMind's research scientist and Daniel Oriol Vinyals quite rarely promoted the work on Twitter (he himself is one of the authors), and said the review is "pretty comprehensive". Many well-known AI scholars also commented on this article. Denny Britz, who once worked as an intern in Google Brain and is engaged in deep reinforcement learning research, said that he is very happy to see that someone combines the first-order logic of Graph with probabilistic reasoning, and this field may usher in a renaissance. Chris Gray, the founder of chip company Graphcore, commented that if this direction continues and results are achieved, it will create a more promising foundation for AI than today's deep learning. Seth Stafford, a Ph.D. in mathematics / MIT postdoctoral research at Cornell University, believes that graph neural networks (Graph NNs) may solve the core problem pointed out by the Turing Award winner Judea Pearl that deep learning cannot do causal reasoning. Open up a more promising direction than deep learning alone So, what is this paper about? DeepMind's views and points are very clear in this paragraph: This is both a submission and a summary, or a kind of unification. We believe that if AI is to achieve the same capabilities as humans, combinatorial generalization must be the top priority, and structured representation and calculation are the key to achieving this goal. Just as innate factors and acquired factors work together in biology, we believe that "hand-engineering" and "end-to-end" learning are not only one of them. Benefit from their complementary advantages. In the paper, the author explores how to use relational inductive biases in deep learning structures (such as fully connected layers, convolutional layers, and recursive layers) to promote the use of entities, relationships, and the components that make up them. Learn the rules. They proposed a new AI module-graph network (graph network), which is the promotion and expansion of various previous neural network methods that operate on graphs. The graph network has a powerful relational induction bias, which provides a direct interface for manipulating structured knowledge and generating structured behavior. The author also discussed how graph networks support relational reasoning and combinatorial generalization, laying the foundation for more complex, interpretable, and flexible reasoning models. Turing Award winner Judea Pearl: The cause and effect of deep learning causal reasoning In early 2018, following the NIPS 2017 debate on "deep learning alchemy", deep learning ushered in another important critic. Judea Pearl, the Turing Award winner and father of the Bayesian Network, published his paper "The Seven Major Sparks of Machine Learning Theoretical Obstacles and Causal Revolutions" at ArXiv, which discusses the current limitations of machine learning theory and gives 7 majors from causal reasoning Inspired. Pearl pointed out that current machine learning systems operate almost entirely in the form of statistics or blind models and cannot be used as the basis for strong AI. He believes that the breakthrough lies in the "causal revolution", which can make a unique contribution to automated reasoning by drawing on a structural causal reasoning model. In a recent interview, Pearl was even more blunt. The current deep learning is nothing more than "curve fitting". "It sounds like blasphemy ... but from a mathematical point of view, no matter how clever you are at manipulating data and how much information you read from it, you still just fit a curve." DeepMind's proposal: integrate traditional Bayesian causal networks and knowledge graphs with deep reinforcement learning how to solve this problem? DeepMind believes that we must start with "Graph Network". Deng Kan, founder of Dashu Yida and Dr. CMU, explained the research background of DeepMind's thesis for us. Dr. Deng Kan introduced that there are three main schools in the machine learning world, Symbolism, Connectionism, and Actionism. The origins of symbolism focus on the study of knowledge expression and logical reasoning. After decades of research, the main achievements of this school at present are one, the Bayesian causal network, and the other, the knowledge graph. The flag bearer of the Bayesian causal network is Professor Judea Pearl, winner of the Turing Award in 2011. But it is said that at the 2017 NIPS academic conference, when the father gave a speech, there were very few listeners. In 2018, the old man published a new book, "The Book of Why", defending the causal network, while criticizing the lack of rigorous logical reasoning process in deep learning. The knowledge graph is mainly promoted by search engine companies, including Google, Microsoft, and Baidu. The goal is to advance search engines from keyword matching to semantic matching. The origin of connectionism is bionics, which uses mathematical models to imitate neurons. Professor Marvin Minsky won the Turing Award in 1969 for promoting neuronal research. A large number of neurons are assembled together to form a deep learning model. The flag bearer of deep learning is Professor Geoffrey Hinton. The most criticized flaw of deep learning models is unexplainable. Behaviorism introduces cybernetics into machine learning. The most famous achievement is reinforcement learning. The bearer of reinforcement learning is Professor Richard Sutton. In recent years, Google DeepMind researchers have combined traditional reinforcement learning with deep learning to achieve AlphaGo, which defeats all human Go masters in today's world. The paper published by DeepMind the day before yesterday proposes to integrate traditional Bayesian causal networks and knowledge graphs with deep reinforcement learning, and to sort out the research progress related to this topic. What is the "Graph Network" proposed by DeepMind Here, it is necessary to give a more detailed introduction to so many "graph networks". Of course, you can also skip this section and look directly at the interpretation below. In the paper "Relational Inductive Bias, Deep Learning, and Graph Networks," the authors explain their "graph networks" in detail. The framework of Graph Network (GN) defines a class of functions for relational reasoning for graphical structure representation. The GN framework summarizes and extends various graph neural networks, MPNN, and NLNN methods, and supports the construction of complex structures from simple building blocks. The main calculation unit of the GN framework is the GN block, that is, the “graph-to-graph†module, which takes graph as input, performs calculation on the structure, and returns graph as output. As described in Box 3 below, the entity is represented by the graph's nodes, edges' relations, and global attributes. The author of the thesis uses "graph" to indicate a directed, attributed multi-graph with global attributes. A node (node) is expressed as Directed: Unidirectional, from the "sender" node to the "receiver" node. Attribute: attribute, can be encoded as a vector (vector), set (set), or even another graph (graph) Attributed: Edges and vertices have attributes associated with them Global attribute: the attribute of graph-level Multi-graph: There are multiple edges between vertices The organization of the blocks of the GN framework emphasizes customizability and comprehensively represents the new architecture of required inductive biases. Use an example to explain GN in more detail. Consider predicting the motion of a set of rubber balls in any gravitational field. Instead of colliding with each other, one or more springs connect them to other balls (or all balls). We will refer to this running example in the definition below to illustrate the graphical representation and calculations performed on it. Definition of "graph" In our GN framework, a graph is defined as a 3-tuple u represents a global attribute; for example, u may represent the gravity field. Algorithm 1: Calculation steps of a complete GN block Internal structure of GN block A GN block contains three "update" functions among them: Figure: Updates in the GN block. Blue indicates the element being updated, and black indicates other elements involved in the update Difficulties of combining knowledge graph and deep learning To combine the knowledge graph with deep learning, Dr. Deng Kan believes that there are several major difficulties. 1. Point vector: The knowledge graph is composed of points and edges. Nodes are used to characterize entities. Entities contain attributes and values. The entities in the traditional knowledge graph are usually composed of conceptual symbols, such as natural language vocabulary. The edge in the traditional knowledge graph connects two single points, that is, two entities. The edge expresses the relationship. The strength of the relationship is expressed by the weight. The weight of the edge of the traditional knowledge graph is usually a constant. If you want to integrate traditional knowledge graph with deep learning, the first thing to do is to realize the differentiability of points. Replacing natural language vocabularies with numerical word vectors is an effective way to achieve differentiable points. The usual approach is to use language models to analyze a large amount of text and find the word vector that best fits the context and semantics for each vocabulary. . However, in the graph, the traditional word vector generation algorithm is not very effective and needs to be modified. 2. Super points: As mentioned above, the edges in the traditional knowledge graph connect two single points and express the relationship between the two single points. This assumption restricts the expressive power of the graph, because in many scenarios, multiple single points are combined together, and there is a relationship with other single points or single point combinations. We call a single point combination a hyper-node. The question is which single points are combined to form a super point? Man-made a priori designation is certainly a solution. From a large amount of training data, it is also an idea to automatically learn the composition of the superpoint through the dropout or regulation algorithm. 3. Super edge: The edges in the traditional knowledge graph express the relationship between points, and the strength of the relationship is expressed by weights, which are usually constant. But in many scenarios, the weight is not constant. As the values ​​of the points are different, the weight of the edge also changes, and it is likely to change nonlinearly. Using a nonlinear function to express the edges of the graph is called a hyper-edge. Deep learning models can be used to simulate nonlinear functions. Therefore, each edge in the knowledge graph is a deep learning model. The input of the model is a superpoint composed of several single points, and the output of the model is another superpoint. If we treat each deep learning model as a tree, the root is the input and the leaves are the output. So a bird's eye view of the entire knowledge graph is actually a forest of deep learning models. 4. Path: When training knowledge maps, including training point vectors, superpoints, and superedges, a training data is often a path walking in the atlas, and by fitting a large number of paths, the most appropriate point vectors, superpoints, and superedges . One problem with training a map using a fitted path is that the training process and the evaluation at the end of the process are disconnected. For example, give you an outline of several articles and corresponding essays, so that you can learn how to write essays. The process of fitting emphasizes imitation word by word. However, the point of evaluating the quality of an article is not that the words and sentences move step by step, but the smoothness of the whole article. How to solve the disconnection between the training process and the final evaluation? A very promising approach is to use reinforcement learning. The essence of reinforcement learning is to give the final evaluation to each intermediate state in the path process through backtracking and discounting methods to evaluate its potential. But the difficulty faced by reinforcement learning is that the number of intermediate states cannot be too large. When there are too many states, the training process of reinforcement learning cannot converge. The solution to the convergence problem is to use a deep learning model to estimate the potential value of all states. In other words, there is no need to estimate the potential values ​​of all states, but only the finite parameters of a model. The article published by DeepMind the day before yesterday proposes to integrate deep reinforcement learning with knowledge graphs, etc., and to sort out a lot of related research. However, the paper does not specify which specific scheme DeepMind prefers. Perhaps, there will be different solutions for different application scenarios, and there is no universal best solution. Graph deep learning is the next hotspot of AI algorithm? Many important real-world data sets come in the form of graphs or networks, such as social networks, knowledge graphs, the World Wide Web, and so on. At present, more and more researchers have begun to pay attention to the processing of this structured data set by neural network models. Combined with a series of papers on graph deep learning published by DeepMind, Google Brain, etc., does it indicate that "graph deep learning" is the next hot spot for AI algorithms? In short, let ’s start with this paper. Laptop Computer,Core I5 Laptop,Metal Slim Laptop,Fhd Laptop C&Q Technology (Guangzhou) Co.,Ltd. , https://www.gzcqteq.com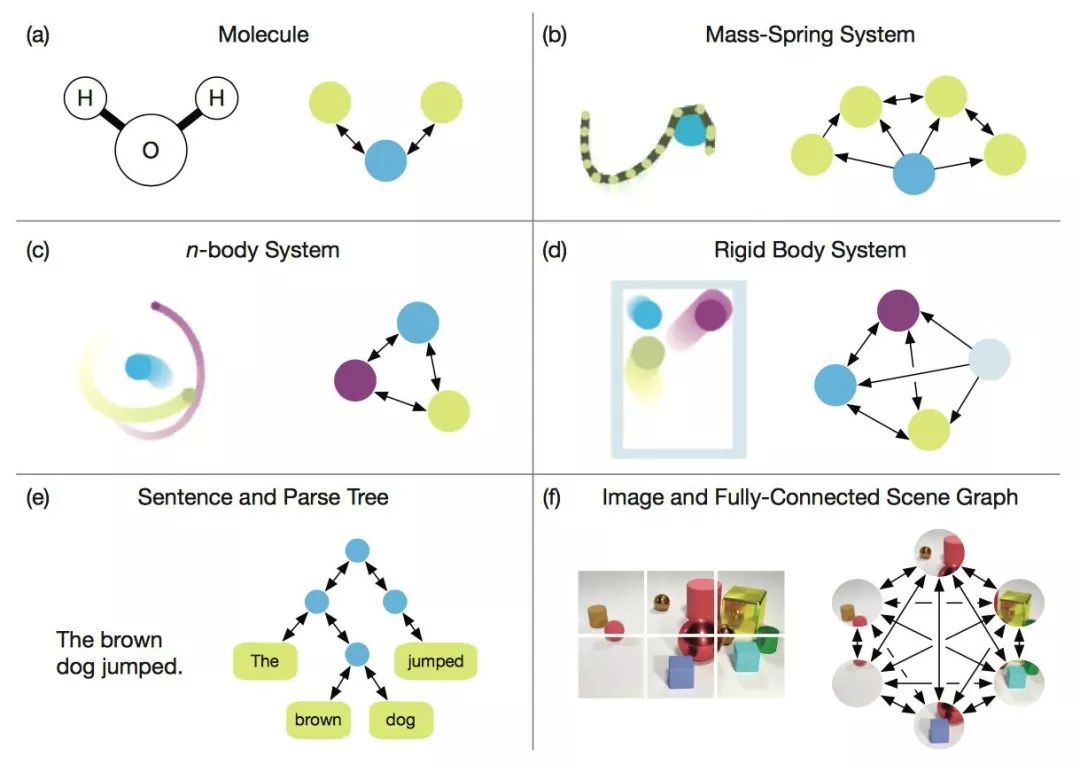





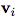 , An edge is expressed as
, An edge is expressed as 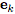 , Global attributes are expressed as u.
, Global attributes are expressed as u. 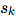 with
with 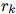 Represents the indices of sender and receiver nodes. details as follows:
Represents the indices of sender and receiver nodes. details as follows: 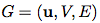
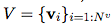 Is a collection of nodes (the cardinality is
Is a collection of nodes (the cardinality is  ), Each of which
), Each of which 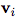
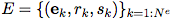 Is the edge (the cardinality is
Is the edge (the cardinality is 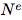 ) Of each of them
) Of each of them 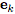
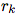
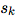

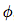 , And three "aggregation" functions
, And three "aggregation" functions