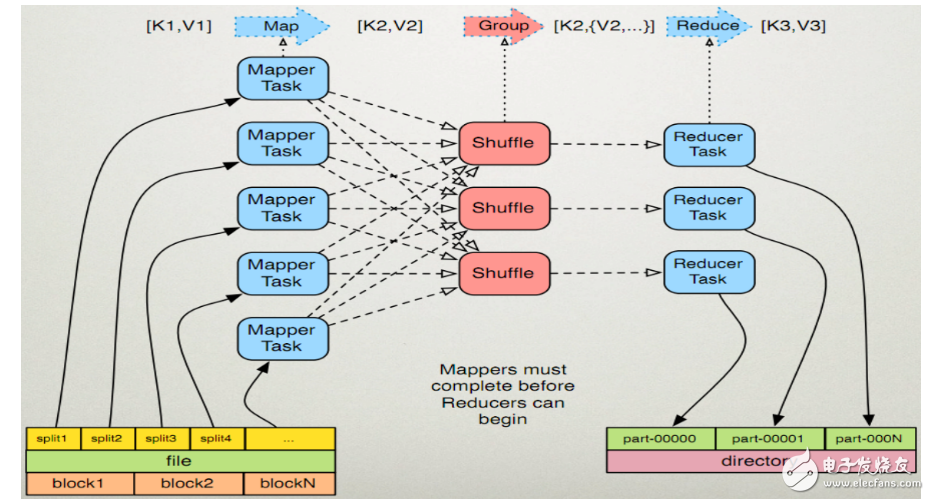
MapReduce is a programming model for parallel operations on large data sets (greater than 1TB). The concepts "Map" and "Reduce" are their main ideas, borrowed from functional programming languages, and borrowed from vector programming languages. It greatly facilitates programmers to run their own programs on distributed systems without distributed parallel programming. The current software implementation specifies a Map function that maps a set of key-value pairs into a new set of key-value pairs, specifying a concurrent Reduce function to ensure that all mapped key-value pairs are centered. Each one shares the same key group. 1. MapReduce is a distributed computing model proposed by Google. It is mainly used in the search field to solve the calculation problem of massive data. 2. MR has two phases: Map and Reduce. Users only need to implement map() and reduce() functions to implement distributed computing. 1.1 Read files in HDFS. Each line is parsed into a "k, v". The map function is called once for each key-value pair. "0, hello you" "10, hello me" 1.2 Overwrite map(), receive the "k,v" generated by 1.1, process it, and convert it to the new "k,v" output. "hello, 1" "you, 1" "hello, 1" "me, 1" 1.3 Partition the "k, v" of the 1.2 output. The default is divided into one area. See "ParTITIoner" for details. 1.4 Sort the data in different partitions (according to k), grouping. Grouping refers to the value of the same key placed in a collection. After sorting: "hello, 1" "hello, 1" "me, 1" "you, 1" After grouping: "hello, {1, 1}" "me, {1}" "you, {1}" 1.5 (Optional) Reduce the data after grouping. See "Combiner" for details. 2.1 The output of multiple map tasks is copied to different reduce nodes through the network according to different partitions. (shuffle) See "shuffle process analysis" for details. 2.2 Combine and sort the output of multiple maps. Override the reduce function, receive the grouped data, and implement your own business logic, "hello, 2" "me, 1" "you, 1" After processing, a new "k, v" output is generated. 2.3 Write the "k,v" of the reduce output to HDFS. Note: To import org.apache.hadoop.fs.FileUTIl.java. 1. Create a hello file and upload it to HDFS. Java code implementation Note: To import org.apache.hadoop.fs.FileUTIl.java. 1. Create a hello file and upload it to HDFS. Figure III 2, then write the code to achieve the number of words in the file statistics (code in the code is commented out, can be omitted, not omitted) 1package mapreduce; 3 import java.net.URI; 4 import org.apache.hadoop.conf.Configuration; 5 import org.apache.hadoop.fs.FileSystem; 6 import org.apache.hadoop.fs.Path; 7 import org.apache.hadoop.io.LongWritable; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Job; 10 import org.apache.hadoop.mapreduce.Mapper; 11 import org.apache.hadoop.mapreduce.Reducer; 12 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 13 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 14 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 15 import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; 16 17 public class WordCountApp { 18 static final String INPUT_PATH = "hdfs://chaoren:9000/hello"; 19 static final String OUT_PATH = “hdfs://chaoren:9000/outâ€; 20 21 public static void main(String[] args) throws Exception { 22 Configuration conf = new Configuration(); 23 FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf); 24 Path outPath = new Path(OUT_PATH); 25 if (fileSystem.exists(outPath)) { 26 fileSystem.delete(outPath, true); 27 } 28 29 Job job = new Job(conf, WordCountApp.class.getSimpleName()); 30 31 // 1.1 specifies where the read file is located 32 FileInputFormat.setInputPaths(job, INPUT_PATH); 33 // Specify how to format the input file and parse each line of the input file into a key-value pair 34 //job.setInputFormatClass(TextInputFormat.class); 35 36 // 1.2 Specify a custom map class 37 job.setMapperClass(MyMapper.class); 38 // The "k,v" type of map output. If the type of "k3, v3" is the same as the type of "k2, v2", it can be omitted. 39 //job.setOutputKeyClass(Text.class); 40 //job.setOutputValueClass(LongWritable.class); 41 42 // 1.3 partition 43 //job.setPartitionerClass(org.apache.hadoop.mapreduce.lib.partition.HashPartitioner.class); 44 // There is a reduce task running 45 //job.setNumReduceTasks(1); 46 47 // 1.4 sorting, grouping 48 49 // 1.5 reduction 50 51 // 2.2 Specify custom reduce class 52 job.setReducerClass(MyReducer.class); 53 // Specify the output type of reduce 54 job.setOutputKeyClass(Text.class); 55 job.setOutputValueClass(LongWritable.class); 56 57 // 2.3 Specify where to write 58 FileOutputFormat.setOutputPath(job, outPath); 59 // Specify the formatting class of the output file 60 //job.setOutputFormatClass(TextOutputFormat.class); 61 62 // Submit the job to jobtracker to run 63 job.waitForCompletion(true); 64 } 65 66 /** 67 * 68 * KEYIN ie K1 represents the offset of the line 69 * VALUEIN or V1 means line text content 70 * KEYOUT ie K2 means words appearing in the line 71 * VALUEOUT or V2 indicates the number of times a word appears in the line, a fixed value of 1 72 * 73 */ 74 static class MyMapper extends 75 Mapper LongWritable, Text, Text, LongWritable { 76 protected void map(LongWritable k1, Text v1, Context context) 77 throws java.io.IOException, InterruptedException { 78 String[] splited = v1.toString().split(""); 79 for (String word : splited) { 80 context.write(new Text(word), new LongWritable(1)); 81 } 82 }; 83 } 84 85 /** 86 * KEYIN ie K2 means words appearing in the line 87 * VALUEIN or V2 indicates the number of words that appear 88 * KEYOUT ie K3 means different words appearing in the line 89 * VALUEOUT or V3 indicates the total number of different words appearing in the line 90 */ 91 static class MyReducer extends 92 Reducer "Text, LongWritable, Text, LongWritable" { 93 protected void reduce(Text k2, java.lang.Iterable《LongWritable》 v2s, 94 Context ctx) throws java.io.IOException, 95 InterruptedException { 96 long times = 0L; 97 for (LongWritable count : v2s) { 98 times += count.get(); 99 } 100 ctx.write(k2, new LongWritable(times)); 101 }; 102 } 103 } 3, after running successfully, you can view the results of the operation in Linux Figure 4 1) Data partitioning and computing task scheduling: The system automatically divides the big data to be processed by a job into a plurality of data blocks, each data block corresponds to a calculation task (Task), and automatically schedules the calculation node to process the corresponding data block. The job and task scheduling functions are mainly responsible for allocating and scheduling compute nodes (Map nodes or Reduce nodes), and are responsible for monitoring the execution status of these nodes and for the synchronization control performed by the Map nodes. 2) Data/code mutual positioning: In order to reduce data communication, a basic principle is localized data processing, that is, a computing node processes the data stored on its local disk as much as possible, which realizes the migration of code to data; when such localized data processing cannot be performed , then look for other available nodes and upload data from the network to the node (data to code migration), but will try to find available nodes from the local rack where the data is located to reduce communication delay. 3) System optimization: In order to reduce the data communication overhead, the intermediate result data will be merged before entering the Reduce node; the data processed by one Reduce node may come from multiple Map nodes. In order to avoid data correlation in the Reduce calculation phase, the Map node outputs the middle. As a result, a certain strategy is needed to perform appropriate partitioning processing to ensure that the correlation data is sent to the same Reduce node. In addition, the system performs some calculation performance optimization processing, such as using multiple backup executions for the slowest computing tasks, and selecting the fastest completion. As a result. 4) Error detection and recovery: In a large-scale MapReduce computing cluster consisting of low-end commercial servers, node hardware (host, disk, memory, etc.) errors and software errors are normal, so MapReduce needs to be able to detect and isolate faulty nodes, and schedule new nodes to take over error nodes. Computational tasks. At the same time, the system will also maintain the reliability of data storage, improve the reliability of data storage with multiple backup redundant storage mechanisms, and timely detect and recover erroneous data. 2.00MM VDSL Cable Connector.SCSI Connector Series. 2.00MM VDSL Cable Connector ShenZhen Antenk Electronics Co,Ltd , https://www.antenkelec.com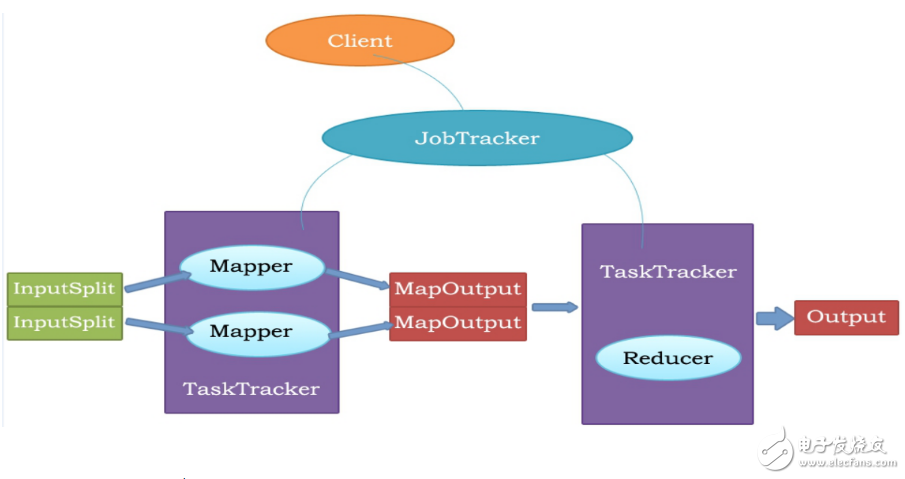
2
Mapreduce Overview