
Deep convolutional neural network is a major contributor behind this wave of AI. Although many people may have heard of this term, for the relevant practitioners or research scholars in this field, a simple understanding is not enough. Recently, Isma Hadji and Richard P. Wildes of the Department of Electrical Engineering and Computer Science at York University published an article, "How Do We Understand Convolutional Neural Networks? 》Thesis:
The first chapter reviews the motivation for understanding the convolutional neural network.
The second chapter describes several multilayer neural networks and introduces the most successful convolutional structures in the application of computer vision.
Chapter 3 introduces the components of the standard convolutional neural network in detail, and analyzes the design of different components from both biological and theoretical perspectives.
Chapter 4 discusses the current trends in the design of convolutional neural networks and the related research work for the visual understanding of convolutional neural networks. It also highlights some of the key issues in the current structure.
Through this article, we hope to help everyone deepen the understanding of the convolutional neural network and have a comprehensive understanding of this important concept.
Chapter One
introduction
This motivation
In the past few years, computer vision research has focused mainly on convolutional neural networks (often abbreviated as ConvNet or CNN), and has achieved the best performance so far in a large number of tasks such as classification and regression. Although the history of these methods can be traced back many years ago, the theoretical understanding of these methods and the interpretation of the results are comparatively shallow.
In fact, many achievements in the field of computer vision regard CNN as a black box. Although this method is effective, the interpretation of the results is ambiguous, and this cannot meet the needs of scientific research. Especially when these two issues are complementary:
(1) The learning aspect (such as the convolution kernel). What did it learn in the end?
(2) Model structure design aspects (such as the number of convolutional layers, the number of convolution kernels, the pooling strategy, and the selection of non-linear functions), why are some combinations better than others? Solving the answers to these questions not only helps us understand the convolutional neural network better, but also further enhances its engineering applicability.
In addition, current CNN implementation methods require a large amount of training data, and the design of the model has a great influence on the final result. A deeper theoretical understanding should reduce the model's dependence on data. Although a large amount of research has focused on the realization of convolutional neural networks, the results of these studies have so far been limited to the visualization of internal processing of convolution operations to understand the differences in convolutional neural networks. Layer changes.
The goal of this article
In response to the above issues, this article will review several current best multi-level convolutional structure models. More importantly, this article will also summarize the various components of the standard convolutional neural network through different methods and introduce the biological or rational theoretical basis they are based on. In addition, this article will also introduce how to try to understand the internal changes of the convolutional neural network through visualization methods and case studies. Our ultimate goal is to show the reader in detail every convolutional layer operation involved in a convolutional neural network, highlighting the most advanced convolutional neural network models and illustrating issues that still need to be addressed in the future.
Chapter two
Multi-layer network structure
In recent years, before the success of deep learning or deep neural networks, the most advanced method of computer vision recognition system is mainly composed of two steps, these two steps are separate but complementary: First, we need to manually design operations (such as roll The product, local or global coding method) converts the input data into a suitable form. This type of input transformation is usually to obtain a compact or abstract representation of the input data, while also manually designing some invariants according to the needs of the current task. With this conversion, we can characterize the input data into a more easily separable or recognizable form, which helps in subsequent identification and classification. Second, the converted data is usually used as an input signal for classifiers (such as support vector machines). In general, the performance of any classifier is affected by the transformed data quality and the transformation method used.
The emergence of multi-layer neural network architecture brings a new way to solve this problem. This multi-layer structure can not only train the target classifier, but also directly learn the required transformation operations from the input data. This type of learning is often referred to as characterization learning. When it is applied to a deep or multi-layer neural network structure, we call it deep learning.
Multilayer neural networks are defined as a computing model that extracts useful information from hierarchical abstract representations of input data. In general, the goal of designing a multi-layer network structure is to highlight the important information of the input data at the high level, and at the same time, to make those less inconsequential information changes more robust.
In recent years, researchers have proposed many different types of multi-layer architectures, and most multi-layer neural networks are based on stacking, combining some linear and non-linear function modules into a multi-layer structure. This chapter will cover the most advanced multilayer neural network architecture in computer vision applications. Among them, artificial neural network is the focus that we need to pay attention to, because this kind of network structure is very prominent. For convenience, we will refer to such networks directly as neural networks below.
Neural Networks
The standard neural network structure is usually composed of an input layer x, an output layer y, and a plurality of hidden layers h, each of which is also composed of a plurality of cells, as shown in the following figure. In general, each hidden element hj accepts the input of all elements of the previous layer and combines them by weights. The mathematical form of the nonlinear combination is as follows:
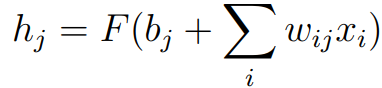
Wij is a weight value used to control the strength of the connection between the input unit and the hidden unit, bj is the offset of the hidden unit, and F is a nonlinear function such as the Sigmoid function.
Deep neural networks can be considered as examples of Rosenblatt sensors and multilayer perceptrons. Although neural network models have existed for many years (since the 1960s), they have not been widely used. There are many reasons for this, and the main reason is that the sensor can't be simulated by the outside world because it can't simulate a simple operation like XOR, which further hinders the researchers' research on the sensor.
Until recently, some researchers have extended simple sensors to multilayer neural network models. In addition, the lack of proper training algorithm will also delay the training progress of perception, and the proposed back propagation algorithm also makes the neural network model popular. More importantly, the multilayer neural network structure relies on a large number of parameters, which means that we need a large amount of training data and computing resources to support the model training and learning parameter process.
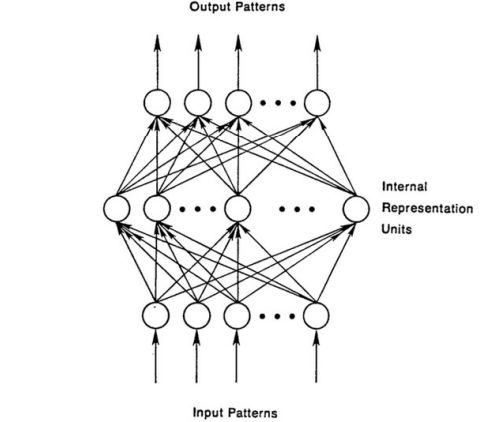
Standard neural network structure diagram
The proposal of a restricted Boltzmann machine (RBM) is an important contribution in the field of deep neural networks. Restricted Boltzmann machines can be viewed as two-layer neural networks that only allow the network to be stacked in a feedforward manner. The neural network can be regarded as a model of hierarchical unsupervised pretraining using a restricted Boltzmann machine. In the image recognition task, this unsupervised learning method mainly includes three steps: First, in the image For each pixel, for xi and initialized wij, offset bj, hidden layer state hj, the probability can be defined as:
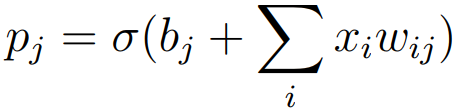
Where σ(y) = 1 / (1 + exp(-y)).
Second, as shown in the above formula, once all hidden states are set randomly, we can use the probability 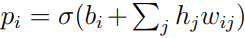 Set each pixel to 1 to reconstruct the image.
Set each pixel to 1 to reconstruct the image.
Then, the hidden unit will update the error of the correction unit by reconstructing the weights and deviations:
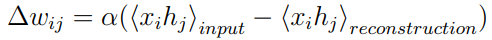
Where α is the learning rate and (xihj) represents the number of occurrences of the pixel xi in the hidden unit hj. The entire training process will repeat N times or until the error falls to the preset threshold τ. After training one level, use its output as input for the next level, and then repeat the above process to train the next level. Normally, after all layers in the network are pre-trained, they will further fine-tune the marker data by back-propagating the error by gradient descent. Using this hierarchical unsupervised pre-training approach allows deep neural network structures to be trained without a large amount of labeled data. Because the unsupervised pre-training with the restricted Boltzmann machine can provide an effective way for the initialization of model parameters. The first successful application of the restricted Boltzmann machine was the dimensionality reduction for face recognition. They were treated as self-encoders.
The automatic encoder mainly introduces different regularization methods to prevent the model from learning some insignificant data features. Some current excellent encoders include sparse autoencoders, denoised autoencoders (DAEs) and compressed autoencoders (CAEs). The sparse autoencoder allows the size of the intermediate code representation (ie, the encoder generated by the input) to be greater than the size of the input while normalizing the output of the negative phase through a sparse representation. In contrast, the denoising self-encoder changes the goal of the code reconstruction itself, tries to reconstruct a clean, non-noisy input version, and obtains a more powerful representation. Similarly, compressed self-encoders are similar to denoised self-encoders by punishing the most sensitive units of noise.
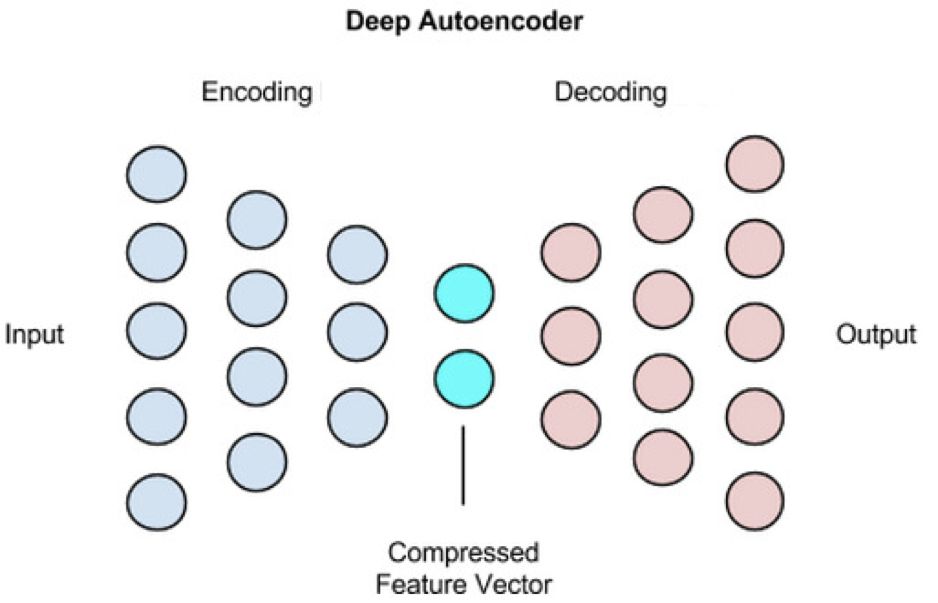
Standard self-encoder structure
Recurrent neural network
The circulatory neural network is the most successful multi-layer neural network model (RNN) for handling serial data related tasks. The RNN, whose schematic diagram is shown in the figure below, can be considered as a special type of neural network. The input of the hidden unit is obtained from the data observed in the current time step and its state combination at the previous time step. to make. The output of a recurrent neural network is defined as follows:
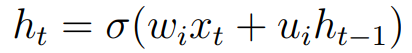
Where σ represents some nonlinear function and wi and ui are network parameters that control the relative importance of current and past information.
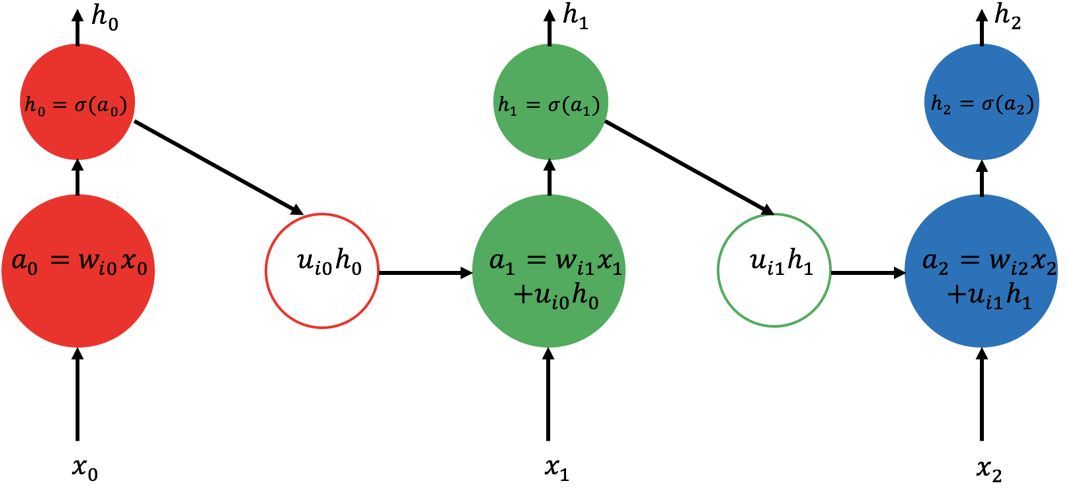
Standard cyclic neural network structure diagram
The input of each cycle unit will consist of the current time input xt and the previous time ht-1. The new output representation can be calculated by the above formula and passed to other layers in the recurrent neural network.
Although the circulatory neural network is a powerful multi-layer neural network model, its main problem is the long-term dependence of the model on time. Due to the gradient explosion or the gradient disappears, this restriction will lead to the model training process in the process of network return. Unsteady changes in the error. In order to correct this difficulty, the long-term memory network (LSTM) was introduced.
Long Term Short Term Memory Network (LSTM) Schematic Diagram The following figure shows a memory unit or memory unit that stores memory information over time. The LSTM's memory cells are used to read or write information from the gating mechanism. It is worth noting that LSTM also contains oblivion gates, meaning that the network can delete some unnecessary information. In summary, the structure of the LSTM consists mainly of three differently controlled gates (input gates, oblivious gates, and output gates) and the state of the memory cells. The input gate is controlled by the current input xt and the previous state ht-1, which is defined as follows:
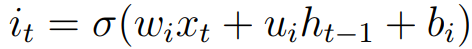
Among them, wi, ui, bi denote weights and deviations, which are used to control the weights associated with the input gates. σ is usually a Sigmoid function. Similarly, Oblivion Gate is defined as follows:
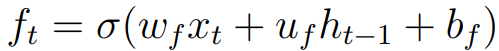
Correspondingly, weights and deviations are controlled by wf, uf, bf. It can be said that the most important point of LSTM is that it can cope with the challenge of uneven propagation of errors in the network when the gradient disappears or the gradient explodes. This capability is achieved by adding the combination of the state of the forgotten gate and the input gate to determine the state of the memory cell.
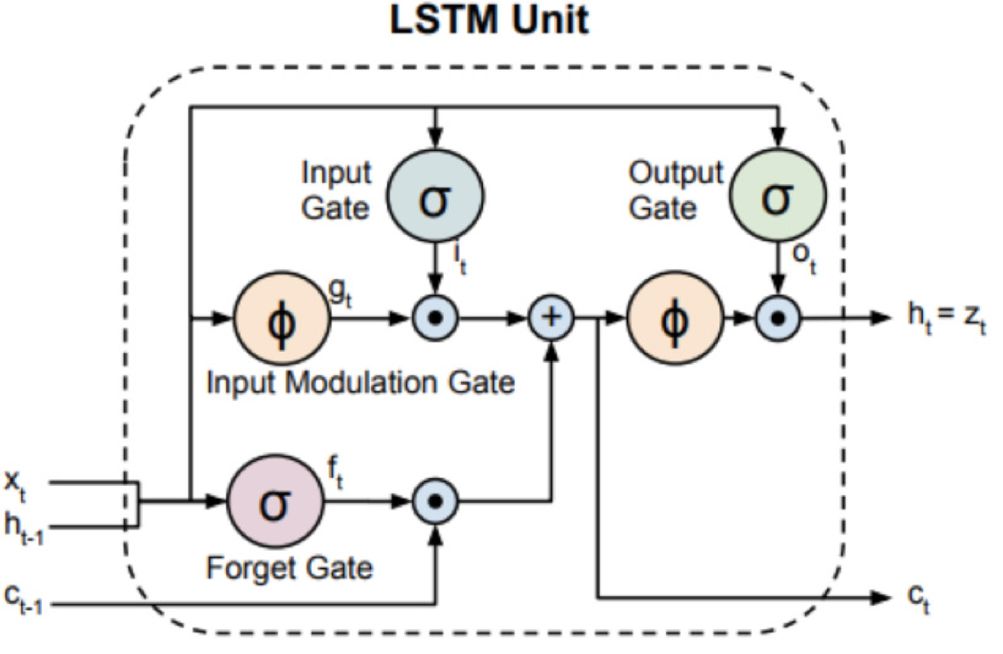
Standard long-term and short-term memory network structure
The input of each cycle unit will consist of the current time input xt and the previous time ht-1, and the network return value will be fed to the next time ht. The final output of the LSTM is determined by the input gate it, the oblivion gate ft and the output gate ot and the memory cell status ct.
Convolutional neural network
ConvNets are special types of neural networks that are particularly suitable for computer vision applications because they have a strong abstract representation of local operations. Two key factors to promote the successful application of convolutional neural network structures in computer vision:
First, the convolutional neural network can exploit the high correlation between the 2D structure of the image and adjacent pixels of the image, thus avoiding the use of one-to-one connections between all pixel units (ie, like most fully connected neural networks), This facilitates the use of grouped local connections. In addition, the convolutional neural network structure relies on the feature sharing principle. As shown in the figure below, the output of each channel (or the output feature map) is generated by the convolution of the same filter at all positions. Compared to the standard neural network structure, this important characteristic of convolutional neural networks relies on few model parameters.
Standard convolutional neural network structure diagram
Second, the convolutional neural network also introduces a pooling step, which guarantees the translation invariance of the image to some extent, which makes the model unaffected by the position change. It is also worth noting that the pooling operation allows the network to have a greater receptive field so that it can accept greater input. The increase in receptive fields will allow the network to learn more deeply to the more abstract feature representations. For example, for the target recognition task, the shallow layer in the convolutional network will learn some edge and corner features of the image, and at the deeper level, the features of the entire target can be learned.
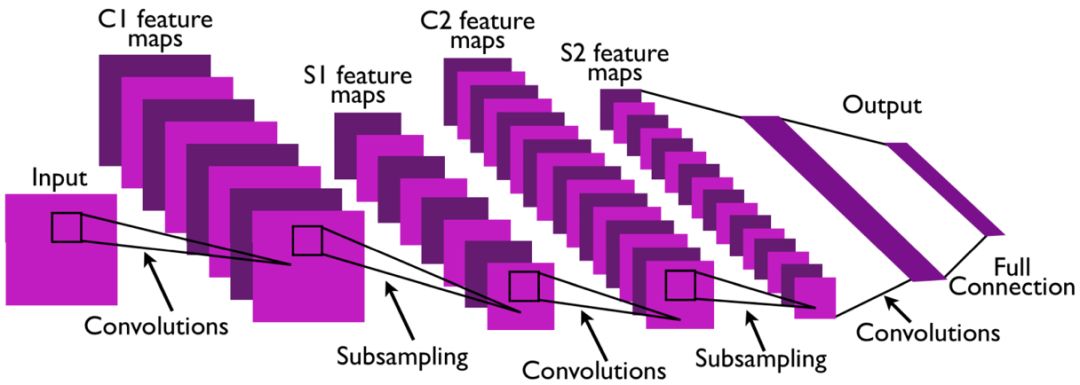
The structure of the convolutional neural network was originally inspired by the biological vision mechanism, just as the working principle of the human visual cortex described by Hube in his groundbreaking research. Subsequently, Neocognitron, proposed by Fukushima, is a predecessor of the convolutional neural network. It relies on a local connection method and consists of a cascade of K neural network layers. Each neural network consists of S-cell units, U sl, and complex networks. The cells are arranged in an alternating manner. This alternate distribution is designed to mimic the processing mechanism in simple cells in biology. The schematic structure is shown in the figure below.
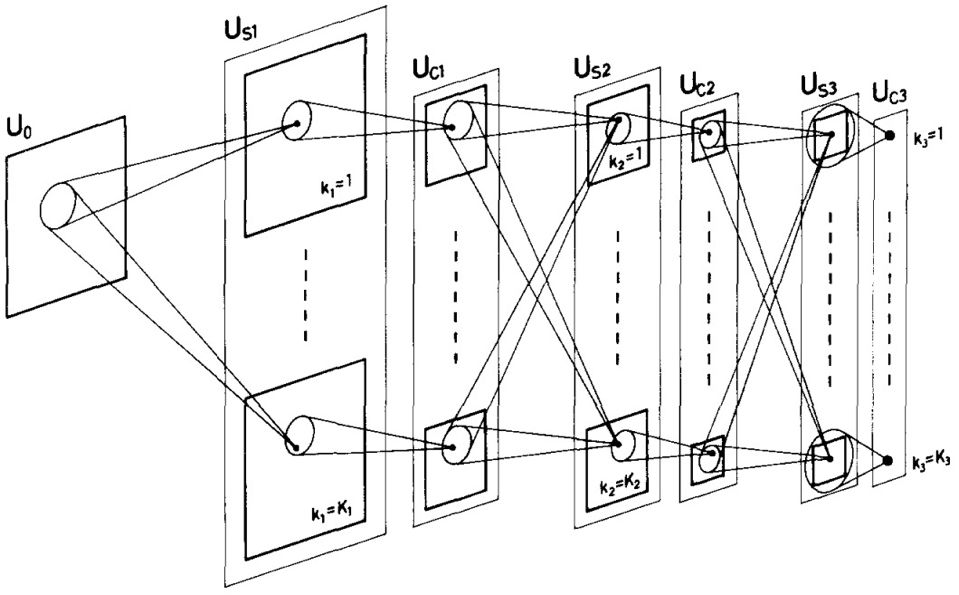
Neural Sensor Structure
In addition, after the convolution operation, a non-linear change unit is followed. A common non-linear function is the correction linear unit ReLu, and its mathematical expression is as follows:
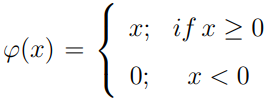
After the nonlinear transformation, the pooling unit is usually introduced. The average pooling operation is one of the commonly used pooling operations, and the characteristics of the surrounding pixels are taken into consideration comprehensively by averaging the pixel values ​​in the receptive field. The maximum pooling is used to extract the most important feature information between adjacent pixels, avoiding the model learning some insignificant features. Classical convolutional networks consist of four basic processing layers: convolutional layers, nonlinear transformation layers, normalized layers, and pooled layers.
In recent years, the convolutional neural network structure applied in the field of computer vision is mostly based on the LeNet convolution model structure proposed by Lecun in 1998 for handwritten letter recognition. One of the keys to LeNet is to join the back-propagation process to learn convolutional parameters more efficiently. Compared with a fully connected neural network, although the convolutional neural network has its unique advantages, its severe dependence on tag data is also one of the main reasons why it has not been widely used. Until 2012, with the release of large ImageNet data sets and the increase in computing power, people regained their interest in convolutional neural networks.
Generate against network
The generation of confrontation networks was first introduced in 2014 as a new type of multi-layer neural network model. This model structure fully reflects the power of multi-layer network architecture. Although there aren't many different network building blocks for generating confrontation networks, this kind of network structure has some specialities. The key is to introduce an unsupervised learning method, which makes the training and learning of models no longer rely on a large amount of markup data.
A standard generation countermeasures model consists of two main subnetworks: generating network G and discriminating network D. As shown in the figure below, both subnetworks are pre-defined multi-layer network structures (both models were originally proposed Multi-layer fully connected network). After the alternate confrontation training, the goal of the discrimination network is to identify the authenticity between the generated data labels of the generated network and the real data labels, and the goal of the generation network is to generate more optimized data to discriminate the network by “spoofing†and the final result of the training. It is the purpose of making the generated data truly messy.
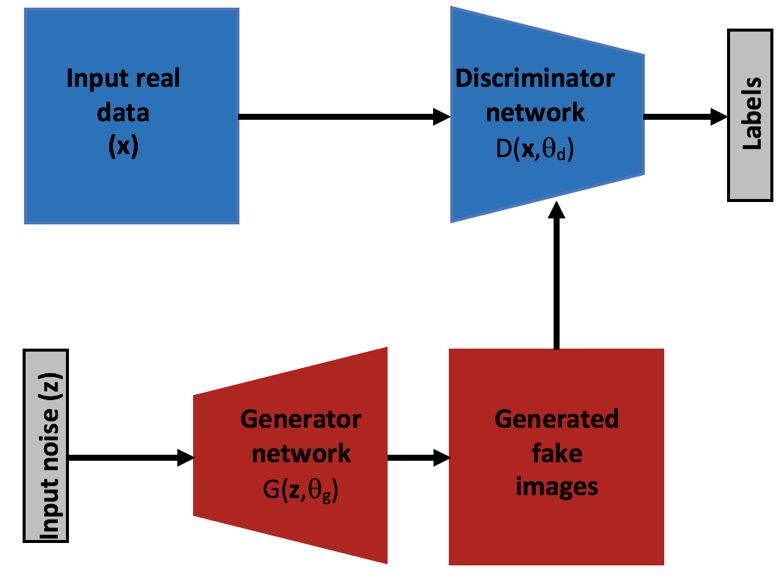
Universal Generation Network Structure
Since its launch, confrontation networks have received extensive attention and research due to their powerful multi-layer network structure and unique unsupervised learning methods. Successful applications of GAN include: text-to-image synthesis (where the network input is the text description of the image to be rendered); the generation of super-resolution images, that is, the generation of realistic high-resolution images with lower resolution input; image restoration, That is, use GAN to generate missing information from the input image; texture synthesis, that is, generate realistic texture features from the input noise.
Multi-layered network training
As mentioned before, the success of various multilayered neural network structures currently depends to a large extent on the progress of network training and learning processes. Usually, neural network training first needs to perform multi-layer unsupervised pre-training. Then, the pre-trained model is supervised. The training process is based on the gradient back-propagation principle and the back propagation network error. Correct the parameter values ​​of the modified model to optimize the network structure and output.
Transfer learning
One of the benefits of multi-layer neural network architecture is that the features learned by the model have universal applicability across data sets and across different tasks. In a multi-layer network structure, as the level increases, the learned feature representation is usually from simple to complex, from local to global development. Therefore, features extracted at low levels are often suitable for a variety of different tasks, which makes it easier for multi-layer structures to migrate and learn.
Space convolutional neural network
Theoretically, the convolutional neural network can be applied to any dimension of data, and is particularly suitable for two-dimensional image data. Therefore, the convolution structure has received considerable attention in the field of computer vision. With the development of available large-scale data sets and powerful computer capabilities, the application of convolutional neural networks in the field of computer vision is also growing. In this section we will introduce some of the most prominent convolutional neural network structures, including AlexNet, VGGNet, GoogleNet, ResNet, DenseNet, etc. The schematic diagrams are as follows. These architectures are based on the original LeNet.
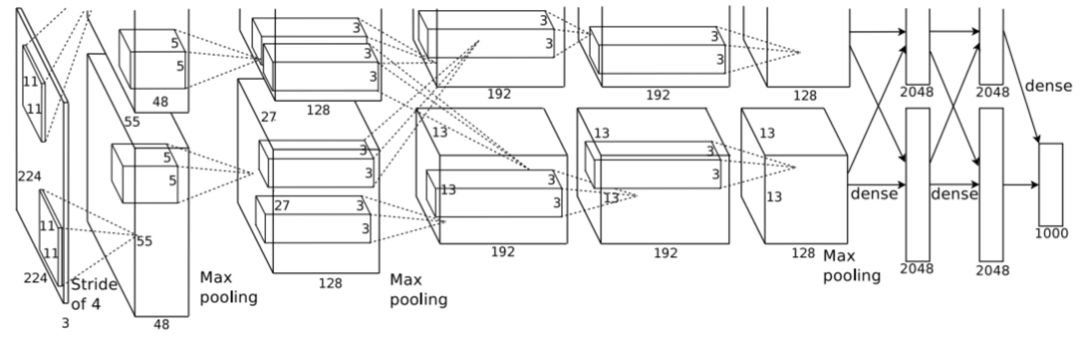
A schematic of the AlexNet model structure. It is worth noting that this structure consists of two branch networks, which are trained in parallel on two different GPUs.
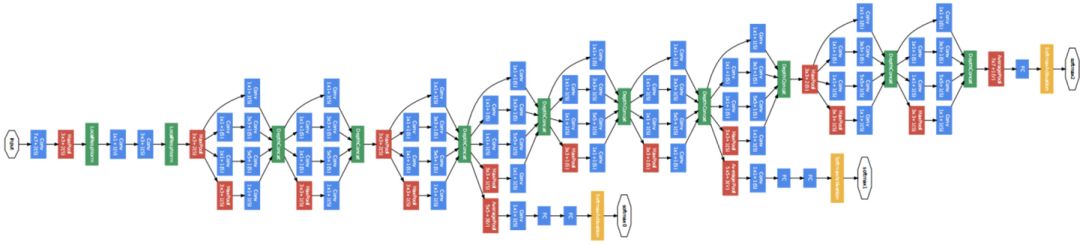
Schematic diagram of GoogleNet model. The model consists of several Inception modules.

ResNet model structure diagram. The model consists of multiple residual modules.
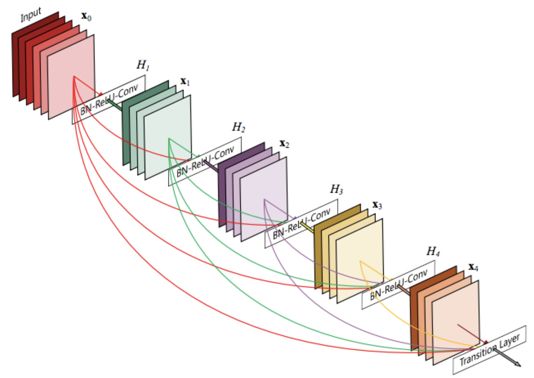

DenseNet model structure diagram. The model consists of a stack of dense modules.
Convolutional neural network without distortion
One of the challenges of using convolutional neural networks is that very large data sets are needed to train and learn all the basic parameters of the model. However, even with the current large-scale datasets, such as ImageNet, which has more than one million image data sets, it still cannot meet the needs of deep convolutional structural training. In general, before the model training, we will deal with the data set through data enhancement operations: that is, change the image by random flip, rotate, and other operations, thereby increasing the number of data samples.
The main advantage of these data enhancement operations is that it makes the network more robust to various image transitions, and this technology is one of the main reasons for AlexNet's success. Therefore, in addition to the above method of changing the network architecture to simplify training, other research efforts aim at introducing a novel module structure to better train the model. An excellent structure for maximizing process invariance is the Spatial Transformation Network (STN). Specifically, this network structure uses a novel learning module that increases the invariance of the model for unimportant spatial transformations, such as those caused by different viewpoints during object recognition. The model structure consists of three sub-modules: a positioning module, a grid generation module, and a sampling module, as shown in the following figure.
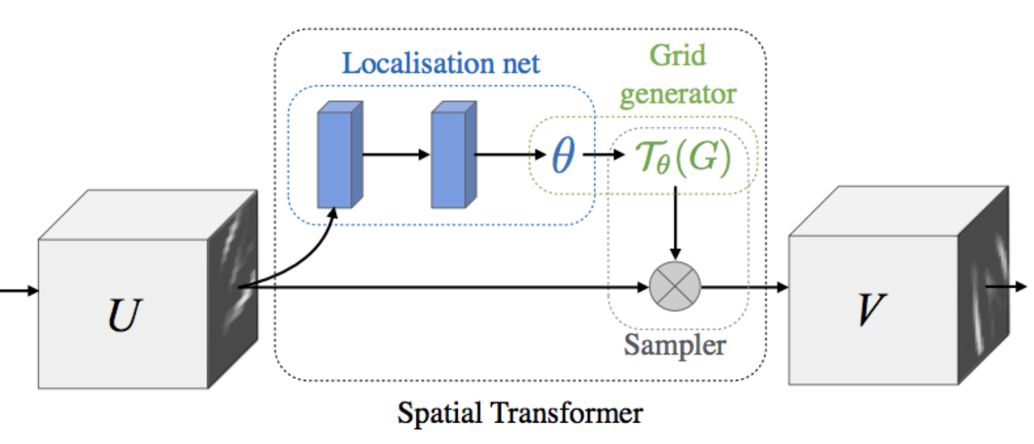
Spatial transformation network structure diagram
Target Location in Convolutional Neural Networks
In addition to the simple task of target recognition and classification, in recent years, the convolutional structure has performed equally well in tasks with precise target positioning, such as target detection and semantic segmentation tasks. Full convolutional network (FCN) is one of the most successful convolutional structures, mainly used for image semantic segmentation. As the name suggests, FCN does not use full-connected layers, but instead converts them to convolutional layers whose receptive fields cover the underlying feature map of the entire convolutional layer. More importantly, the network can recover the full resolution of the last layer of the image by learning an upsampling or deconvolution filter. The structure is shown in the figure below.
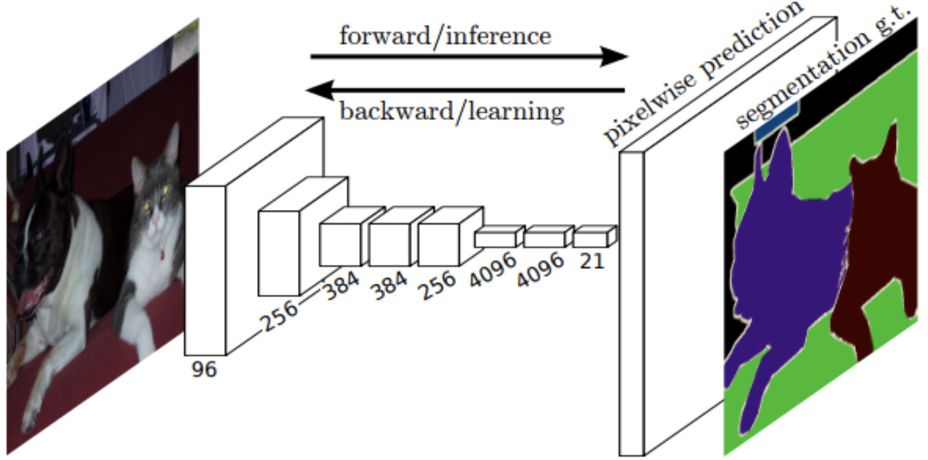
Full convolutional network structure diagram. After the upsampling operation, a full-resolution feature map is obtained at the last layer of the model, and softmax is applied to classify each pixel and generate a final segmentation result.
In FCN, the semantic segmentation problem is transformed into a dense, pixel-by-pixel classification problem that is implemented by projection. In other words, each pixel is associated with the softmax layer, and semantic segmentation of the image is achieved by pixel grouping by class. It is even more noteworthy that in this work, the upsampling operation is applied to the characteristics of the lower structural layer and plays a crucial role. Since the lower-level features are more inclined to capture finer details, the upsampling operation allows the model to be more precisely segmented. In addition, an alternative to the deconvolution filter is to use an expansive convolution, that is, an upsampling sparse filter, which helps the model to learn a higher resolution feature map while maintaining the number of parameters.
R-CNN is the earliest convolutional structure used for target detection tasks. It is a convolutional neural network (RPN) with regional recommendations. It achieved the most advanced detection results in the initial target detection task, especially the use of areas. The proposed selective search algorithm detects potential areas that may contain targets, and performs some transformations on these proposed areas to match the input size of the convolutional structure. After feature extraction in the convolutional neural network, it is finally sent to the SVM for classification. Non-maximal values ​​are used to suppress the performance of the optimization model in post-processing steps.
Subsequently, target detection models such as Fast R-CNN, Faster R-CNN, and Mask R-CNN were proposed based on the original R-CNN structure. It can be said that the application of convolutional neural networks in target detection is centered around the R-CNN structure.
Time domain convolutional neural network
As mentioned above, the remarkable performance of convolutional neural networks in the application of computer vision two-dimensional space has led to the study of 3D spatio-temporal applications. The temporal convolutional structure proposed in many literatures is usually just a two-dimensional convolutional structure that attempts to extend from the spatial domain (x,y) to the time domain (x,y,t). The time domain neural network structure has three different forms: LSTM-based time-domain convolutional network, 3D convolutional neural network, and dual-flow convolutional neural network. The model structure is shown in the figure below.
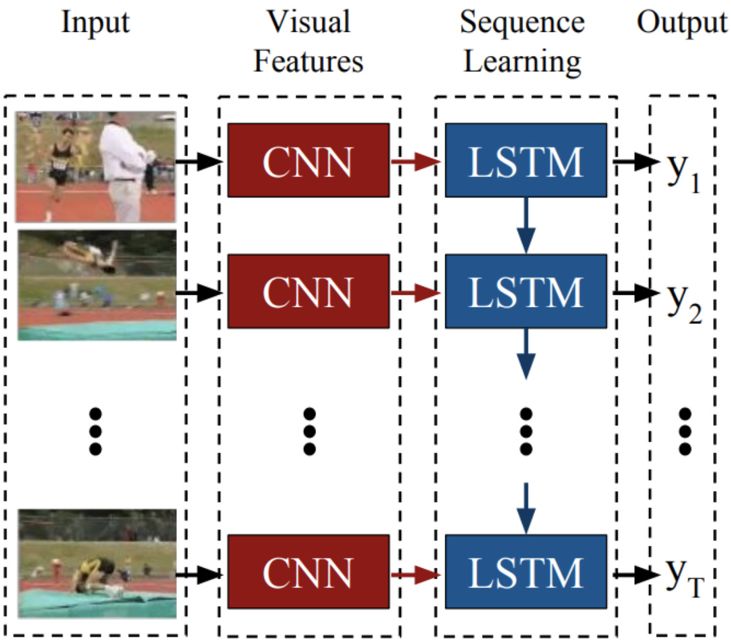
LSTM based time domain convolutional neural network. In this model, the input of the model is composed of each frame of data of the video stream.
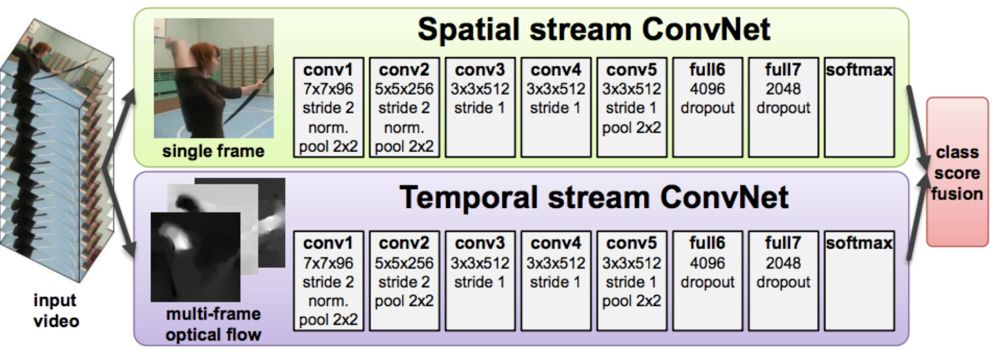
Double stream convolutional neural network. The model takes RGB optical flow data as input.
Summary
Compared to manually designed features or shallow feature representations, multi-layer convolutional structures are one of the most advanced and attractive structures in computer vision today. In general, most of the model structures are based on four common building blocks, namely convolutions, nonlinear elements, normalization, and pooling operations. Although these excellent convolutional models have achieved optimal performance in most computer vision tasks, their common drawbacks are still rather limited in the understanding of convolutional internal operations, feature characterization, and rely on large-scale data sets and model training. The process lacks precise performance limits and the definition of hyperparameters. These hyperparameters include the size of the filter, the nonlinear function, the pooling operation parameters, and the choice of model layers. Next we will further discuss the selection of these hyperparameters in the convolutional neural network design process.
third chapter
Understand the building blocks of convolutional neural networks
Considering that there are still a lot of unresolved issues in the convolutional neural network field, in this chapter we will discuss the role and significance of each layer of convolutional network processing operations in typical cases. In particular, we will give reasonable ideas from a theoretical and biological perspective. Explanation.
Convolution layer
The core layer of a convolutional neural network is the convolutional layer, which is the most important step of the model. In general, convolution is a linear, translation-invariant operation that is implemented by locally weighting the input signal. The set of weights is determined according to the point spread function, and different weight functions can reflect the different properties of the input signal.
In the frequency domain, associated with the point spread function is a modulation function, which indicates that the frequency components of the input can be modulated by scaling and phase shift. Therefore, choosing the right convolution kernel will help the model to obtain the most significant and important feature information in the input signal.
Nonlinear unit
Multilayer neural networks are usually highly nonlinear models, and rectification usually introduces a non-linear function (also called an activation function) that applies a non-linear function to the convolutional output. The purpose of introducing the correction unit is, on the one hand, for the best and most appropriate model explanation; on the other hand, it is to make the model learn faster and better. The commonly used nonlinear functions mainly include Logistic function, tanh function, Sigmoid function, ReLU and its variants LReLU, SReLU, EReLU, etc. The function image is shown in the figure below.
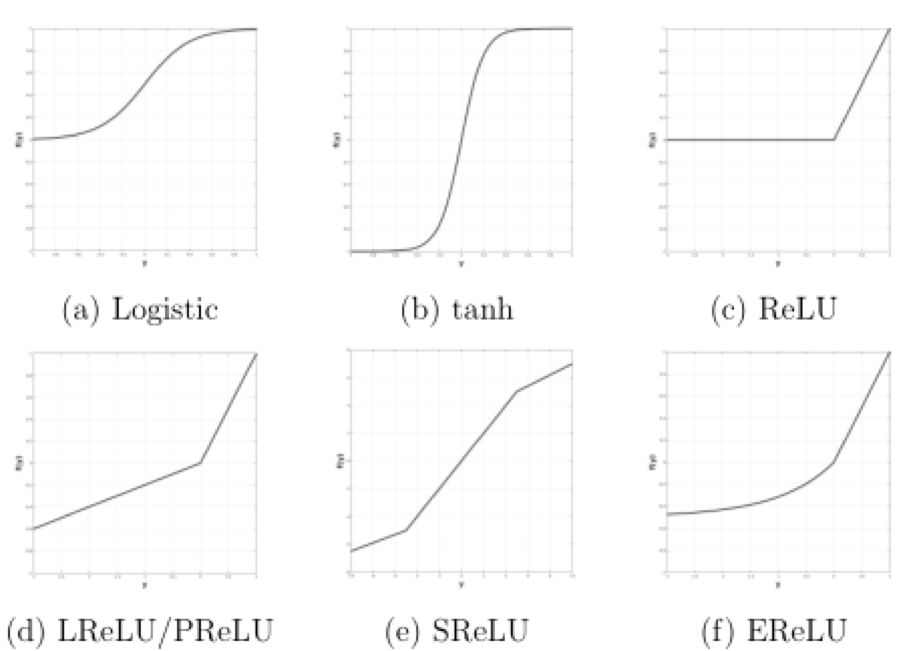
Nonlinear activation function in multi-layer network structure
Normalization
As mentioned above, multilayer neural networks are highly nonlinear models because of the cascaded nonlinear operations in these multilayer networks. In addition to the modified nonlinear elements discussed above, normalization is also an important non-linear processing module in convolutional neural network structures. The most widely used normalized form is the so-called Local Response Normalization (LRN). In addition, there are batch normalization, divisive normalization, and the like.
Pooled operation
Almost all convolutional neural networks include pooling operations. The pooling operation is to extract changes in features at different locations and sizes while aggregating the responses of different feature maps. As with the first three components of the convolutional structure, the pooling operation was also inspired by biology and theoretical support. The average pooling and maximum pooling are the two most widely used pooling operations. The pooling effects are shown in the following figure.

Gabor feature changes after average pooling operation

Gabor feature changes after maximum pooling operation
Chapter Four
Current research status
The elaboration of the role of each group in the convolutional neural network structure highlights the importance of the convolutional module. This module is mainly used to capture the most abstract feature information. Relatively speaking, our understanding of convolution module operation is very vague, and the understanding of the tedious calculation process is not thorough. In this chapter we will try to understand the different layers of convolutional network learning and different visualization methods. At the same time, we will also focus on the issues that remain to be resolved in these areas.
▌ Current trend
Although various excellent convolution models have achieved optimal performance in various computer vision applications, the progress in understanding the working methods of these model structures and exploring the effectiveness of these structures is still rather slow. Nowadays, this issue has attracted the interest of many researchers. For this reason, many studies have proposed methods for understanding the convolutional structure.
In general, these methods can be divided into three directions: visual analysis of the learned filters and extracted feature maps, ablation studies inspired by the biovisual cortical understanding method, and introduction of principal components. The analytics design and analysis of the network minimization learning process, we will briefly summarize these three methods.
Visual analysis of convolutions
The first method of convolution visualization is a data set-centric approach because the convolution operation relies on the input from the data set to probe the network to find the largest response unit in the network. The first application of this method is DeConvNet. Visualization is implemented in two steps. First, a convolutional structure receives several images from dataset a and records the maximum response of the feature maps input in the dataset. Second, these feature maps use a deconvolutional structure through inverse convolution. The operation module performs the "deconvolution" operation by transposing the filter characteristics learned in the convolution operation, thereby realizing the visual analysis of the convolution. The schematic diagram of the deconvolution operation is as follows:
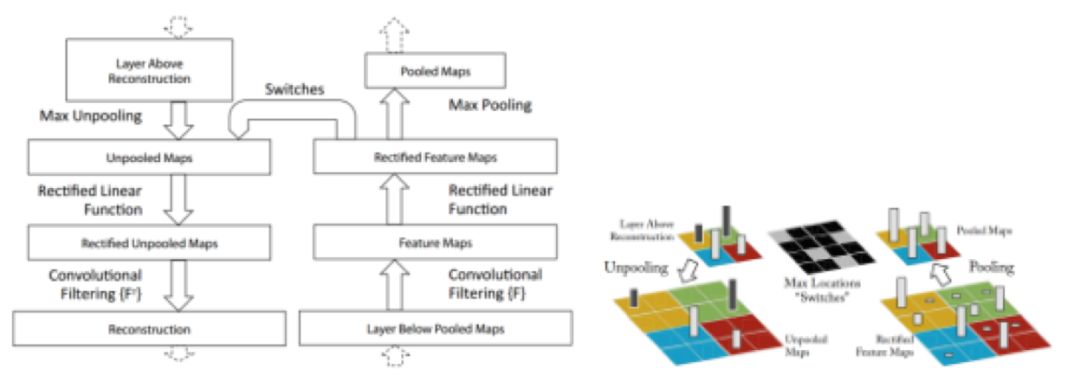
Deconvolution building block
The second method of convolution visualization is called a network-centric approach because it only uses network parameters and does not require any data for visualization. This method was first applied to the visual analysis of deep confidence networks and was later applied to convolutional network structures. Specifically, this convolution visualization is achieved by composite images that will maximize the response of certain neurons (or filters).
Convolutional Ablation Learning
Another popular visualization method is the use of so-called network ablation studies. In fact, many well-known convolutional structures include model ablation research experiments. The purpose is to isolate the different parts of the convolutional structure into a network to see how deleting or adding certain modules simulates the overall performance. Ablation research can guide researchers to design a network structure with better performance.
Convolution control design
Another way to understand the convolutional structure is to add prior knowledge in the design of the network to minimize the learning of model parameters. For example, some methods are to reduce the number of filters to be learned per layer convolutional layer, and to simulate rotation invariance using a filter that the converted version learns in each layer. Other methods rely on the learning process of replacing the filter with the basic set, rather than learning the filter parameters, and their goal is to learn how to combine the basic set to form an effective filter at each layer. In addition, there are some ways to design an interpretable network by completely designing the convolutional network manually and adding specific prior knowledge in the network design phase for specific tasks.
Urgent problem to be solved
Through the above content, we have summarized some key techniques of the convolutional model and how to better understand the convolutional structure. In the following, we will further discuss some issues still to be solved in the convolution model field.
Several key issues to be solved in the research method based on convolution visualization:
First of all, it is very important to develop a more objective visual evaluation method, which can be achieved by introducing evaluation indicators to evaluate the quality or meaning of the generated visual images.
In addition, although it seems that network-centric convolution visualization methods are more promising (because they do not rely on the model structure itself in generating visualization results), there is also a lack of a standardized evaluation process. One possible solution is to use an assessment benchmark to evaluate the network visualization results generated under the same conditions. Such standardized methods, in turn, can also implement index-based assessment methods rather than current interpretive analysis.
Another development direction of visual analysis is to simultaneously visualize multiple elements of the network to better understand the distribution of feature representations in the model and even follow a control approach.
Several key issues that are still to be solved in the research method based on the ablation study:
Use a common, systematic organization of data sets. We must not only solve common challenges in the field of computer vision (such as viewing angles and changes in light), but also must deal with more complex categories of issues (such as image textures, parts and target complexity, etc.). In recent years, there have been some such data sets. On such datasets, using an ablation study, supplemented by confusion matrix analysis, can identify the wrong module in the convolutional structure in order to achieve a better understanding of the convolution.
In addition, the analysis of how multiple collaborative ablations affect the performance of the model is a subject of intense research. Such research can also help us understand how independent units work.
Compared to the completely learning-based approach, there are still some controlled methods that allow us to have a deeper understanding of the operations and characterization of these structures, and therefore have great research prospects. These interesting research directions include:
Layer-by-layer fixed network parameters and analysis of the impact on network behavior. For example, a layer of convolution kernel parameters are fixed at a time based on prior knowledge of a particular task to analyze the applicability of the convolution kernel in each convolution layer. This step-by-step learning style helps to reveal the role of convolutional learning and can also be used as an initialization method to minimize training time.
Similarly, the design of the network structure (such as the number of layers or the number of filters in each layer) can be studied by analyzing the characteristics of the input. This method helps to design the structure that is most suitable for the model.
Finally, applying the controlled method to the network can systematically study the effects of other aspects of the convolutional neural network. In general, we focus on the parameters learned by the model, so less attention is paid to this aspect. For example, we can study the effects of various pooling strategies and residual connections with most of the parameters fixed.
SHENZHEN CHONDEKUAI TECHNOLOGY CO.LTD , http://www.siheyidz.com