UTF-8 (8-bit Unicode Transformation Format) is a variable length character encoding for Unicode, also known as Unicode. Created in 1992 by Ken Thompson. It has now been standardized as RFC 3629. UTF-8 encodes Unicode characters with 1 to 6 bytes. It can be used on the web page to display Chinese Simplified and Traditional Chinese and other languages ​​(such as English, Japanese, Korean). If the UNICODE character is represented by 2 bytes, encoding to UTF-8 is likely to require 3 bytes. And if the UNICODE character is represented by 4 bytes, encoding into UTF-8 may require 6 bytes. It may be too much to encode a UNICODE character with 4 or 6 bytes, but rarely encounters such a UNICODE character. ASCII is a computerized coding system based on the Latin alphabet, mainly used to display modern English and other Western European languages. It is the most versatile single-byte encoding system available today and is equivalent to the international standard ISO/IEC 646. In the computer, all data is stored in binary numbers (because the computer uses high and low levels to represent 1 and 0, respectively), for example, 52 letters like a, b, c, d (including uppercase), and 0, 1 and other numbers and some commonly used symbols (such as *, #, @, etc.) should also be represented by binary numbers when stored in the computer, and which binary numbers are used to represent which symbols, of course Everyone can agree on their own set (this is called coding), and if you want to communicate with each other without causing confusion, then everyone must use the same coding rules, so the relevant American standardization organization has issued ASCII code. Uniformly stipulates which binary numbers are used to represent the above common symbols. I have been ignorant of the various encoding methods of characters. What ANSI UNICODE UTF-8 GB2312 GBK DBCS UCS... is not very dizzy, if you read this article carefully, you can clearly understand them. Let's go! A long time ago, a group of people decided to use eight transistors that could be opened and closed to form different states to represent the world. They see that the eight switch states are good, so they call this "bytes." Later, they made some machines that could handle these bytes. The machine started, and many states could be combined in bytes, and the state began to change. They see that this is good, so they call this machine "computer." Start the computer only in the United States. A total of 256 (2 to the 8th power) different states can be combined in a total of eight bits. They set the 32 states in which the number starts from 0 to specify a special purpose. Once the bytes agreed upon by the terminal and the printing opportunity are transmitted, some agreed actions are to be made. When it encounters 00x10, the terminal will change the line. When it encounters 0x07, the terminal will beep to people. For example, if 0x1b is encountered, the printer will print the reverse word, or the terminal will display the letters in color. They see this very well, so they call these byte states below 0x20 "control code". They also put all the spaces, punctuation, numbers, and uppercase and lowercase letters in consecutive byte states, and compiled them to No. 127, so that the computer can store English characters in different bytes. Everyone saw this, they all felt very good, so everyone called this program the ANSI "Ascii" code (American Standard Code for Information Interchange). At the time, all computers in the world used the same ASCII scheme to save English text. Later, like the construction of the Babylon Tower, computers were used all over the world, but many countries did not use English. Many of their letters were not in ASCII. In order to save their text on the computer, they decided to adopt 127. The space after the number indicates these new letters and symbols. It also adds a lot of shapes for drawing the horizontal lines, vertical lines, crosses, etc., and the serial number is programmed to the last state 255. The character set from 128 to 255 is called the "extended character set". Since then, greedy humans have no new state to use, and US imperialism may not have thought that people in third world countries also hope to use computers! When Chinese people get computers, there is no byte state that can be used to represent Chinese characters. Moreover, there are more than 6,000 commonly used Chinese characters to be saved. But this is hard to beat the wisdom of the Chinese people. We are bluntly canceling the singular symbols after the 127th. It is stipulated that a character smaller than 127 has the same meaning as the original, but two characters greater than 127 are connected together. When it is a Chinese character, the first byte (which he calls the high byte) is used from 0xA1 to 0xF7, and the next byte (low byte) is from 0xA1 to 0xFE, so that we can combine more than 7000. Simplified Chinese characters. In these codes, we also included mathematical symbols, Roman Greek letters, and Japanese pseudonyms. The numbers, punctuation, and letters that were originally in ASCII were all re-encoded by two bytes. This is the "full-width" character that is often said, and those that are below 127 are called "half-width" characters. The Chinese people saw this very well, so they called this Chinese character scheme "GB2312". GB2312 is a Chinese extension to ASCII. But there are too many Chinese characters in China. We soon discovered that there are many people whose names cannot be played here, especially some national leaders who are very troublesome. So we have to continue to find out the unused code bits of GB2312 to use it honestly and unkindly. Later, it was not enough, so I simply stopped asking the low byte to be the inner code after the 127 number. As long as the first byte is greater than 127, it is fixed to indicate that this is the beginning of a Chinese character, regardless of whether it is followed by an extended character set. The content inside. The resulting coding scheme after expansion is called the GBK standard. GBK includes all the contents of GB2312, and at the same time adds nearly 20,000 new Chinese characters (including traditional characters) and symbols. Later, ethnic minorities also used computers, so we expanded and added thousands of new minority characters. GBK was expanded to GB18030. From then on, the culture of the Chinese nation can be passed down in the computer age. Chinese programmers saw that the standard for encoding Chinese characters was good, so they called them "DBCS" (Double Byte Charecter Set). In the DBCS series of standards, the biggest feature is that two-byte long Chinese characters and one-byte long English characters coexist in the same set of encoding schemes, so the programs they write must pay attention to the strings in order to support Chinese processing. The value of each byte, if the value is greater than 127, then the character in a double-byte character set appears. At that time, computer monks who were blessed and programmed would read the following spell hundreds of times a day: "A Chinese character counts two English characters! A Chinese character counts two English characters..." Because at that time, each country came up with a set of its own coding standards like China. As a result, no one knows who's coding, and no one supports the coding of others. Even the mainland and Taiwan are only 150 nautical miles apart. The brother regions of the same language also adopted different DBCS coding schemes. At that time, the Chinese wanted to let the computer display Chinese characters, and they had to install a "Chinese character system" to deal with the display and input of Chinese characters. But the fortune-telling program written by Taiwan's ignorant feudal figures must be installed with another set of "Etienne Chinese Character System" that supports BIG5 encoding. If the wrong character system is installed, the display will be messed up! What should I do? And there are those poor people in the world's national forests who can't use computers for a while. What about their words? Really the computer's Babylonian proposition! At this time, the archangel Gabriel appeared in time - an international organization called ISO (International Standardization Organization) decided to address this issue. The approach they took was simple: scrapped all regional coding schemes and re-created a code that included all the cultures, all letters and symbols on Earth! They intend to call it "Universal Multiple-Octet Coded Character Set", referred to as UCS, commonly known as "UNICODE". When UNICODE began to be developed, the memory capacity of the computer was greatly developed, and space was no longer a problem. Therefore, ISO directly stipulates that two bytes must be used, that is, 16 bits to uniformly represent all characters. For those "half-width" characters in ascii, the UNICODE packet retains its original encoding, but its length is from the original 8. The bits are expanded to 16 bits, while the characters of other cultures and languages ​​are all re-encoded. Since the "half-width" English symbol only needs to use the lower 8 bits, its upper 8 bits are always 0, so this atmospheric scheme will waste twice as much space when saving English text. At this time, the programmers who came from the old society began to find a strange phenomenon: their strlen function could not be relied on, a Chinese character is no longer equivalent to two characters, but one! Yes, starting with UNICODE, whether it is a half-width English letter or a full-width Chinese character, they are all unified "one character"! At the same time, it is also a unified "two bytes", please note the difference between the terms "character" and "byte", "byte" is an 8-bit physical storage unit, and "character" is A culturally relevant symbol. In UNICODE, one character is two bytes. The era of a Chinese character counting two English characters is almost over. In the past when multiple character sets existed, companies that used multi-language software had a lot of trouble. In order to sell the same software in different countries, they had to bless the double-byte character set spell when they were regionalized. Not only must you be careful not to make mistakes, but also transfer the text in the software to different character sets. UNICODE is a good package for them, so starting with Windows NT, MS took the opportunity to change their operating system and changed all the core code to a version that works in UNICODE mode. At the beginning, the WINDOWS system finally has no need to install a variety of native language systems to display the characters of all cultures in the world. However, UNICODE is not considered to be compatible with any of the existing coding schemes. This makes GBK and UNICODE completely different in the internal coding of Chinese characters. There is no simple arithmetic method to remove text content from The UNICODE encoding is converted with another encoding, which must be done by looking up the table. As mentioned earlier, UNICODE is represented by two bytes as a single character. In total, it can combine 65535 different characters, which probably covers the symbols of all cultures in the world. If it doesn't matter, it doesn't matter. ISO has already prepared the UCS-4 solution. It is simple to say that four bytes are used to represent a character, so that we can combine 2.1 billion different characters (the highest position has other uses). This can probably be used on the day the Galaxy Federation was founded! When UNICODE came, the rise of computer networks came together. How UNICODE is transmitted on the network is also a problem that must be considered. Therefore, many UTF (UCS Transfer Format) standards for transmission have appeared. As the name suggests, UTF8 is 8 times. The bits are transmitted, and UTF16 is 16 bits at a time, but for the reliability of transmission, there is no direct correspondence from UNICODE to UTF, but some algorithms and rules are required to convert. Computer monks who have been blessed by network programming know that there is a very important problem when transmitting information in the network. For the way of reading high and low data, some computers use the low-first method, such as the one used by our PC. The INTEL architecture, while others use the high-first transmission method. When exchanging data in the network, in order to check whether the two sides have the same understanding of the high and low levels, a very simple method is adopted, that is, at the beginning of the text stream. Send a flag to the other party - if the following text is high, then send "FEFF", otherwise, send "FFFE". Do not believe that you can open a file in UTF-X format in binary mode, to see if the first two bytes are these two bytes? Speaking of this, let's talk about a very strange phenomenon: when you create a new file in the notepad of Windows, enter the word "Unicom", save, close, and then open again, you will find these two The word has disappeared, replaced by a few garbled! Oh, some people say that this is the reason why China Unicom is not moving. In fact, this is because GB2312 encoding and UTF8 encoding have caused the encoding collision. From the Internet, a conversion rule from UNICODE to UTF8 is introduced: Unicode UTF-8 0000 - 007F 0xxxxxxx 0080 - 07FF 110xxxxx 10xxxxxx 0800 - FFFF 1110xxxx 10xxxxxx 10xxxxxx For example, the Unicode encoding of "Han" is 6C49. 6C49 is between 0800-FFFF, so use a 3-byte template: 1110xxxx 10xxxxxx 10xxxxxx. Write 6C49 as binary is 1001, divide this bit stream into 0110 110001 001001 according to the segmentation method of the three-byte template, and replace the x in the template in turn, get: 1110-0110 10-110001 10-001001, ie E6 B1 89, This is the encoding of its UTF8. When you create a new text file, the encoding of Notepad is ANSI by default. If you input Chinese characters in ANSI encoding, then it is actually the encoding method of GB series. Under this encoding, the internal code of "Unicom" is: C1 1100 0001 Aa 1010 1010 Cd 1100 1101 A8 1010 1000 Did you notice? The first two bytes, the beginning of the third four bytes are "110" and "10", which is exactly the same as the two-byte template in the UTF8 rule, so when you open Notepad again, the note I mistakenly think that this is a UTF8 encoded file, let us remove the first byte of 110 and the second byte of 10, we get "00001 101010", then align each bit, make up the preamble 0, you get "0000 0000 0110 1010", sorry, this is 006 of UNICODE, which is the lowercase letter "j", and the next two bytes are 0368 after UTF8 decoding, this character is nothing. This is why there is no way for a file with only "Unicom" to display properly in Notepad. And if you enter more words after "China Unicom", the encoding of other words is not necessarily the byte starting at 110 and 10, so when you open it again, Notepad will not insist that this is a UTF8 encoded file. , and will be interpreted in ANSI way, then garbled does not appear. Ok, finally you can answer the question of NICO. In the database, the string type with n prefix is ​​UNICODE type. In this type, two bytes are fixed to represent a character, whether the character is Chinese or English. Or something else? If you want to test the length of the string "abc kanji", in a data type without an n prefix, the string is 7 characters long because a Chinese character is equivalent to two characters. In a data type with an n prefix, the same test string length function will tell you that it is 5 characters, because a Chinese character is a character. ASCII code We know that inside a computer, all information is ultimately represented as a binary string. Each bit has two states, 0 and 1, so eight bins can be combined into 256 states, which is called a byte. That is, a byte can be used to represent 256 different states, each of which corresponds to a symbol, which is 256 symbols, from 0000000 to 11111111. In the 1960s, the United States developed a set of character codes that made uniform rules for the relationship between English characters and binary bits. This is called ASCII code and has been used ever since. The ASCII code specifies a total of 128 characters, for example, the space "SPACE" is 32 (binary 00100000), and the uppercase letter A is 65 (binary 01000001). These 128 symbols (including 32 control symbols that cannot be printed) occupy only the last 7 digits of a byte, and the first 1 digit is uniformly defined as 0. 2, non-ASCII encoding English is enough to encode with 128 symbols, but to represent other languages, 128 symbols are not enough. For example, in French, there are phonetic symbols above the letters, which cannot be represented in ASCII. As a result, some European countries decided to use the highest bit of the idle byte to encode a new symbol. For example, the encoding of é in French is 130 (binary 10000010). In this way, the coding systems used in these European countries can represent up to 256 symbols. However, new problems have arisen here. Different countries have different letters, so even if they use 256 symbols, the letters they represent are different. For example, 130 represents é in the French code, Giul (×’) in the Hebrew code, and another symbol in the Russian code. However, in all of these encoding methods, the symbols represented by 0-127 are the same, and the different ones are only 128-255. As for the texts of Asian countries, the symbols used are even more, and the Chinese characters are as much as 100,000. A byte can only represent 256 symbols, which is definitely not enough. You must use multiple bytes to express a symbol. For example, the common encoding method in Simplified Chinese is GB2312, which uses two bytes to represent a Chinese character, so theoretically it can represent up to 256x256=65536 symbols. The problem of Chinese coding needs to be discussed in a special article. This note is not covered. It is only pointed out here that although all symbols are represented by multiple bytes, the Chinese character encoding of the GB class has nothing to do with the following Unicode and UTF-8. 3.Unicode As mentioned in the previous section, there are multiple encoding methods in the world, and the same binary number can be interpreted as different symbols. Therefore, in order to open a text file, you must know how it is encoded. Otherwise, it will be garbled if it is interpreted in the wrong way. Why are emails often garbled? It is because the sender and the recipient use different coding methods. Imagine if there is a code that includes all the symbols in the world. Each symbol is given a unique encoding, and the garbled problem disappears. This is Unicode, as its name suggests, which is a code for all symbols. Unicode is of course a large collection, and now it can hold more than 1 million symbols. The encoding of each symbol is different. For example, U+0639 represents the Arabic letter Ain, U+0041 represents the English capital A, and U+4E25 represents the Chinese character “strictâ€. For the specific symbol correspondence table, you can query unicode.org or a special Chinese character correspondence table. 4. Unicode issues It should be noted that Unicode is just a set of symbols. It only specifies the binary code of the symbol, but does not specify how the binary code should be stored. For example, the Chinese character "strict" unicode is a hexadecimal number 4E25, which is converted into a binary number with 15 bits (100111000100101), which means that the representation of this symbol requires at least 2 bytes. Representing other larger symbols may require 3 bytes or 4 bytes, or even more. There are two serious problems here. The first question is, how can we distinguish between unicode and ascii? How does a computer know that three bytes represent a symbol, rather than three symbols? The second problem is that we already know that it is enough to use only one byte for English letters. If unicode stipulates that each symbol is represented by three or four bytes, then each English letter must have two before it. Up to three bytes is 0, which is a great waste for storage, and the size of the text file will be two or three times larger, which is unacceptable. The result is: 1) There are multiple storage methods for unicode, that is, there are many different binary formats that can be used to represent unicode. 2) unicode cannot be promoted for a long time until the emergence of the Internet. 5.UTF-8 The popularity of the Internet strongly demands a uniform coding method. UTF-8 is the most widely used unicode implementation on the Internet. Other implementations include UTF-16 and UTF-32, but are basically not used on the Internet. Again, the relationship here is that UTF-8 is one of the implementations of Unicode. One of the biggest features of UTF-8 is that it is a variable length encoding. It can use 1~4 bytes to represent a symbol and change the length of the byte according to different symbols. The encoding rules for UTF-8 are very simple, only two: 1) For single-byte symbols, the first bit of the byte is set to 0, and the next 7 bits are the unicode code for this symbol. So for English letters, UTF-8 encoding and ASCII are the same. 2) For the n-byte symbol (n"1), the first n bits of the first byte are set to 1, the n+1th bit is set to 0, and the first two bits of the following byte are set to 10. The remaining bits that are not mentioned are all unicode codes for this symbol. The following table summarizes the encoding rules, with the letter x indicating the bits of the available encoding. Unicode symbol range | UTF-8 encoding (hex) | (binary) --------------------+----------------------------- ---------------- 0000 0000-0000 007F | 0xxxxxxx 0000 0080-0000 07FF | 110xxxxx 10xxxxxx 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx Below, the Chinese character "strict" is taken as an example to demonstrate how to implement UTF-8 encoding. The known "strict" unicode is 4E25 (100111000100101). According to the above table, 4E25 can be found in the range of the third line (0000 0800-0000 FFFF), so the "strict" UTF-8 encoding requires three bytes. , the format is "1110xxxx 10xxxxxx 10xxxxxx". Then, starting from the last bit of "strict", the x in the format is filled in from the back to the front, and the extra bits are padded with 0. This is obtained, the "strict" UTF-8 encoding is "11100100 10111000 10100101", converted to hexadecimal is E4B8A5. 6. Conversion between Unicode and UTF-8 Through the example in the previous section, you can see that the "strict" Unicode code is 4E25, and the UTF-8 code is E4B8A5. The two are different. The conversion between them can be achieved through the program. On the Windows platform, one of the easiest ways to convert is to use the built-in Notepad applet Notepad.exe. After opening the file, click the "Save As" command in the "File" menu, a dialog box will pop up, and there is a "code" drop-down bar at the bottom. There are four options: ANSI, Unicode, Unicode big endian and UTF-8. 1) ANSI is the default encoding method. For English files, it is ASCII code. For Simplified Chinese files, it is GB2312 code (only for Windows Simplified Chinese version, if it is Traditional Chinese version, it will use Big5 code). 2) Unicode encoding refers to the UCS-2 encoding method, that is, the Unicode code in which characters are directly stored in two bytes. This option uses the little endian format. 3) Unicode big endian encoding corresponds to the previous option. I will explain the meaning of little endian and big endian in the next section. 4) UTF-8 encoding, which is the encoding method mentioned in the previous section. After selecting the "Encoding Method", click the "Save" button and the encoding of the file will be converted immediately. 7. Little endian and Big endian As mentioned in the previous section, Unicode codes can be stored directly in UCS-2 format. Take the Chinese character "strict" as an example. The Unicode code is 4E25 and needs to be stored in two bytes. One byte is 4E and the other byte is 25. When stored, 4E is in front, 25 is in the back, it is the Big endian way; 25 is in the front, 4E is in the back, it is the Little endian way. These two weird names come from the British writer Swift's Gulliver's Travels. In the book, a civil war broke out in the country of the villain. The cause of the war was people's arguments. When eating eggs, it was knocked from the Big-Endian or the Little-Endian. For this matter, six wars broke out before and after, one emperor sent his life, and the other emperor lost the throne. Therefore, the first byte is the "Big endian" and the second byte is the "Little endian". So naturally, there will be a question: How does the computer know which way to encode a file? As defined in the Unicode specification, each file is preceded by a character indicating the encoding order. The name of this character is called "ZERO WIDTH NO-BREAK SPACE" and is represented by FEFF. This is exactly two bytes, and FF is one greater than FE. If the first two bytes of a text file are FE FF, it means that the file is in the big head mode; if the first two bytes are FF FE, it means that the file is in the small header mode. 8. Examples Below, give an example. Open the "Notepad" program Notepad.exe, create a new text file, the content is a "strict" word, followed by ANSI, Unicode, Unicode big endian and UTF-8 encoding. Then, use the "hexadecimal function" in the text editing software UltraEdit to observe the internal encoding of the file. 1) ANSI: The encoding of the file is two bytes "D1 CF", which is the "strict" GB2312 encoding, which also implies that the GB2312 is stored in a large format. 2) Unicode: The encoding is four bytes "FF FE 25 4E", where "FF FE" indicates that it is stored in small header mode, and the real encoding is 4E25. 3) Unicode big endian: The encoding is four bytes "FE FF 4E 25", where "FE FF" indicates that it is a large-head mode storage. 4) UTF-8: The encoding is six bytes "EF BB BF E4 B8 A5", the first three bytes "EF BB BF" indicate that this is UTF-8 encoding, and the last three "E4B8A5" are "strict" The specific encoding, its storage order is consistent with the encoding order. [html] view plaincopy /** Chinese string to UTF-8 and GBK code example */ Public static void tttt() throws Exception { String old = "Mobile Banking"; / / Chinese converted to UTF-8 encoding (hexadecimal string) StringBuffer utf8Str = new StringBuffer(); Byte[] utf8Decode = old.getBytes("utf-8"); For (byte b : utf8Decode) { utf8Str.append(Integer.toHexString(b & 0xFF)); } // utf8Str.toString()=====e6898be69cbae993b6e8a18c // System.out.println("UTF-8 string e6898be69cbae993b6e8a18c converted to Chinese value ======" + new String(utf8Decode, "utf-8"));//-------Mobile bank / / Chinese conversion to GBK code (hexadecimal string) StringBuffer gbkStr = new StringBuffer(); Byte[] gbkDecode = old.getBytes("gbk"); For (byte b : gbkDecode) { gbkStr.append(Integer.toHexString(b & 0xFF)); } // gbkStr.toString()=====cad6bbfad2f8d0d0 // System.out.println("GBK string cad6bbfad2f8d0d0 converted to Chinese value ======" + new String(gbkDecode, "gbk"));//----------Mobile Banking //16-ary string converted to Chinese Byte[] bb = HexString2Bytes(gbkStr.toString()); Bb = HexString2Bytes("CAD6BBFAD2F8D0D0000000000000000000000000"); Byte[] cc = hexToByte("CAD6BBFAD2F8D0D0000000000000000000000000", 20); String aa = new String(bb, "gbk"); System.out.println("aa====" + aa); } [html] view plaincopy/** * Convert a hex string to a byte array * @param hexstr * @return */ Public static byte[] HexString2Bytes(String hexstr) { Byte[] b = new byte[hexstr.length() / 2]; Int j = 0; For (int i = 0; i " b.length; i++) { Char c0 = hexstr.charAt(j++); Char c1 = hexstr.charAt(j++); b[i] = (byte) ((parse(c0) "4) | parse(c1)); } Return b; } Private static int parse(char c) { If (c ">= 'a') Return (c - 'a' + 10) & 0x0f; If (c ">= 'A') Return (c - 'A' + 10) & 0x0f; Return (c - '0') & 0x0f; } [html] view plaincopy/** * Convert byte array to hex string * @param bArray * @return */ Public static final String bytesToHexString(byte[] bArray) { StringBuffer sb = new StringBuffer(bArray.length); String sTemp; For (int i = 0; i " bArray.length; i++) { sTemp = Integer.toHexString(0xFF & bArray[i]); If (sTemp.length() 2) Sb.append(0); Sb.append(sTemp.toUpperCase()); } Return sb.toString(); }
Thermal Overload Relays are protective devices used for overload protection of electric motors or other electrical equipment and electrical circuits,It consists of heating elements, bimetals,contacts and a set of transmission and adjustment mechanisms.
Our Thermal Overload Relays had been divided into five series(as follow),with good quality and most competitive price,had exported into global market for many years:
LR1-D New Thermal Relay
The working principle of the thermal relay is that the current flowing into the heating element generates heat, and the bimetal having different expansion coefficients is deformed. When the deformation reaches a certain distance, the link is pushed to break the control circuit, thereby making the contactor Loss of power, the main circuit is disconnected, to achieve overload protection of the motor.
Thermal Overload Relay,Telemecanique Overload Relay,Thermal Digital Overload Relay,Telemecanique Model Thermal Relay Ningbo Bond Industrial Electric Co., Ltd. , https://www.bondelectro.com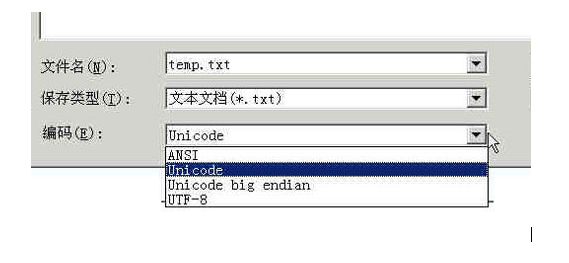
LR2-D Thermal Relay
LR-D New Thermal Relay
LR9-F Thermal Relay
Intermediate Relay
As an overload protection component of the motor, the thermal relay has been widely used in production due to its small size, simple structure and low cost.
111")
Utf8